
비즈니스 로직을 작성하다 보면 일괄적인 포인트 만료 작업, 휴면 계정 처리 혹은 복잡한 데이터 마이그레이션 등 주기적으로 대량의 작업을 수행해야 하는 경우가 생길 수 있습니다. 간단한 작업이라면 크론탭이나 젠킨스를 활용할 수도 있고, 자바 언어 기반이라면 Spring Batch라는 건재한 프레임워크가 존재하여 job 단위로 관리할 수도 있습니다.
비슷한 개념의 오픈소스로 파이썬 기반의 Apache Airflow가 있습니다. Airflow는 Airbnb에서 개발한 데이터 파이프라인 및 스케줄링 플랫폼으로, 2016년부터는 Apache 재단에서 관리하고 있습니다. 발표된지 얼마 되지 않은 따끈따끈한 프레임워크지만 실무에도 꽤 적용이 되면서 현재는 꽤 많은 레퍼런스를 찾아볼 수 있습니다. 아래서 Airflow의 구성 요소 및 작동 방식에 대해 알아봅시다.
1. DAG
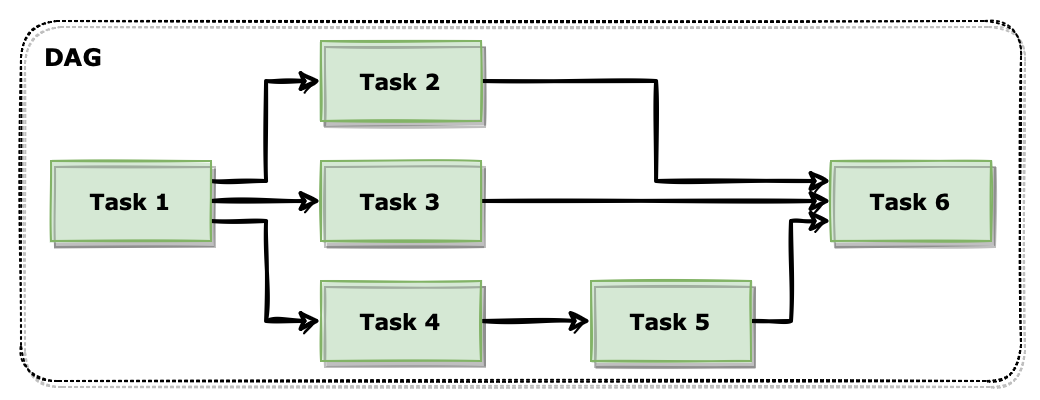
Airflow에서는 기본적인 작업의 단위를 Task 라고 합니다. 하나의 Task 마다 파이썬 코드 실행이나 쉘 스크립트, 도커 이미지 실행, 이메일 발송과 같은 독립된 작업을 정의할 수 있습니다. 이러한 Task들이 연결된 집합을 DAG 라고 합니다. DAG 안에서 Task들을 작업 흐름에 맞게 배치하여 실행 로직을 만들 수 있습니다. DAG는 파이썬 언어로 작성 가능한데 고유 id, 실행 주기, 작업 실패시 알림 등을 정의할 수 있습니다.
DAG는 ‘Directed Acyclic Graph’의 앞 글자를 가져온 단어인데 이름에서도 볼 수 있듯이 단방향으로 연결된 비순환 구조를 추구하고 있습니다.
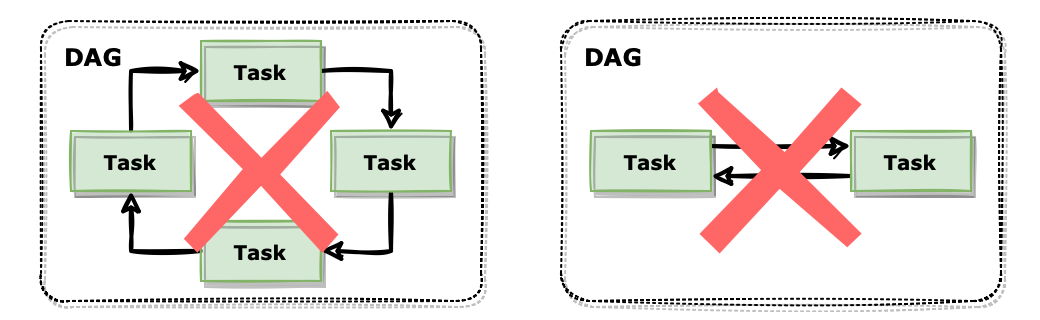
위와 같이 각 작업끼리 순환하는 구조로 연결되어있거나 양방향으로 연결된 구조는 Airflow에서는 적합하지 않습니다.
2. Architecture
Airflow는 webserver, scheduler, worker 프로세스가 메타 데이터베이스, DAG 파일과 상호작용하는 구조로 구성되어 있습니다.
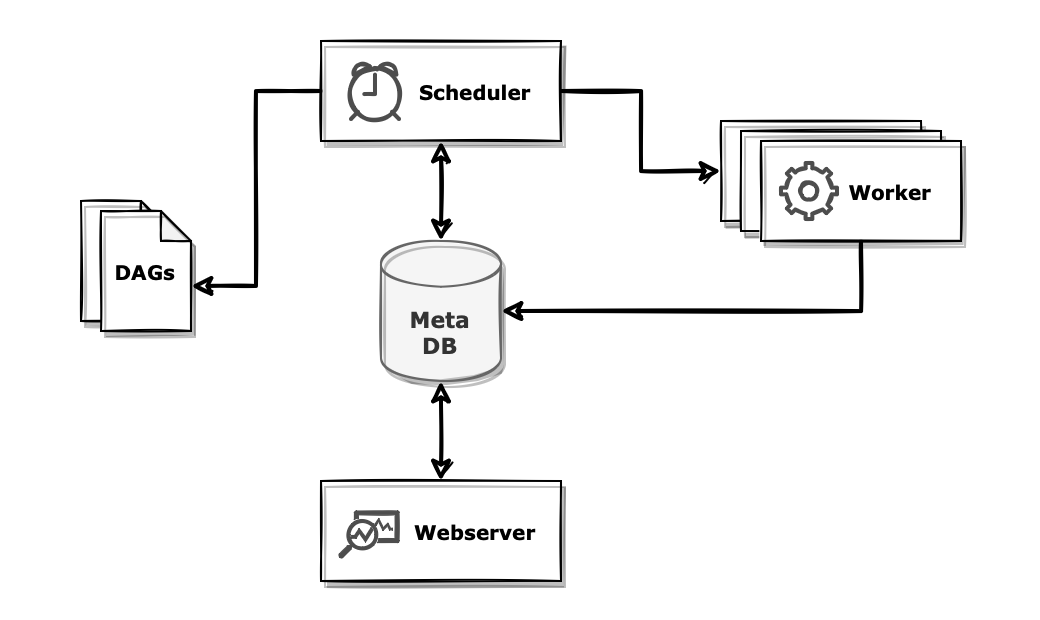
웹서버(webserver)는 모니터링을 위한 인터페이스입니다.
Flask 어플리케이션 기반으로 구성되어 있으며 DAG의 상태, 실행 로그 등을 확인할 수 있습니다. 필요한 경우에는 수동으로 작업을 실행시킬 수도 있습니다.
CeleryExecutor로 구성된 경우라면 보조적으로 flower를 활용할 수도 있습니다. 기본적으로 5555포트로 실행됩니다.
스케줄러(scheduler)는 작성된 DAG 파일을 정기적으로 파싱하여 DAG 및 Task 정보를 메타 DB에 저장합니다. 새로 추가된 DAG를 발견하면 동일하게 파싱합니다. 또한 정해진 시간이 되면 DAG가 실행되도록 각 Task를 대기열에 배치합니다.
워커(worker)는 실제 Task를 실행하는 프로세스입니다. 스케줄러로부터 실행 신호를 받으면 해당된 DAG 파일을 읽어와 작업을 실행합니다. 실행이 완료되면 메타 DB에 실행 결과를 기록합니다.
메타 데이터베이스는 Airflow에서 일어나는 모든 상황이 기록되는 저장소입니다. 스케줄러로부터 파싱된 DAG 정보, Task 실행 결과와 같은 정보들이 저장되어 있습니다.
3. Scheduler
Airflow의 핵심 컴포넌트는 스케줄러라고 할 수 있습니다. 크게 두 가지 일을 하는데 첫 번째는 파이썬으로 작성된 DAG 파일을 읽고 구문 분석하여 주기적으로 DB에 갱신하는 작업이고, 두 번째로는 실행 시기가 된 작업이 실행되도록 대기열에 배치하는 역할을 합니다.
3.1 DAG Processor Manager
스케줄러 프로세스는 구동 시에 DagFileProcessorManager 프로세스를 별도로 실행하여 DAG 파일 관리를 담당시킵니다. 해당 프로세스는 파이썬으로 작성된 DAG 파일의 전반적인 전처리를 담당하는데 무한 루프를 돌면서 아래와 같이 정해진 작업을 반복합니다.
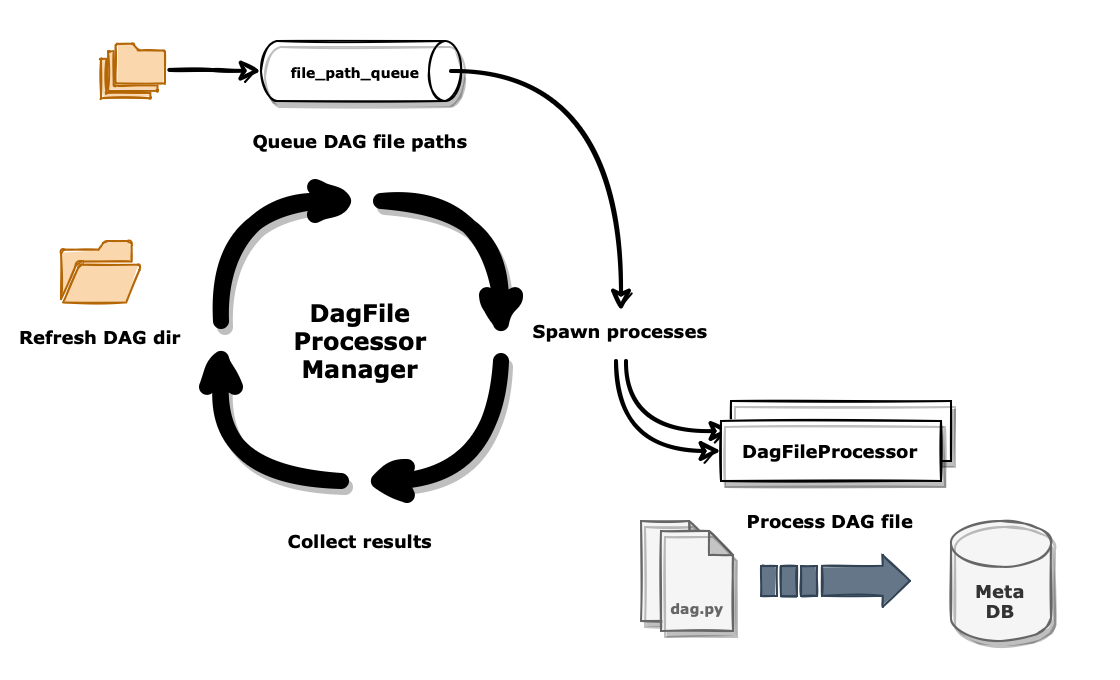
- 디렉토리를 스캔하여 DAG 파일이 존재하는 path 리스트를 갱신합니다. DAG 파일이 삭제된 경우 DAG 정보를 메타 데이터베이스에서 제거합니다.
- DAG 디렉토리 path 리스트 중에서 파싱 시점이 된 DAG를 선별하여 큐(queue)에 넣습니다.
이전 단계에서 새로 추가된 DAG 파일이 존재했다면 해당 DAG도 큐에 넣습니다.
큐는 파이썬 내장 객체
collections.deque타입으로 되어있습니다. - 큐에 처리할 DAG 파일이 존재한다면 DagFileProcessor 프로세스를 spawn 하여 처리할 DAG 파일을 할당합니다. 하나의 프로세스는 하나의 DAG 파일을 담당하여 작업을 진행합니다.
- DagFileProcessor에서 DAG 파일을 구문 분석하여 메타 데이터베이스에 저장합니다. DAG 및 Task 정보들은 JSON 객체로 파싱 되어 ‘serialized_dag’ 테이블에, 파이썬 코드에 입력된 정보들(스케줄 주기, 태그, 백필 등)을 비롯한 메타 정보들은 ‘dag’ 테이블에, 파이썬 코드 전문은 ‘dag_code’ 테이블에 각각 저장됩니다.
- 위 작업을 계속 반복합니다.
3.2 Task Scheduler
스케줄러 메인 프로세스에서는 DAG 및 Task 들의 전반적인 생명 주기를 관리합니다. 처음 프로세스가 실행되면 DagFileProcessorManager 프로세스 및 executor를 실행시킨 후, 무한 루프를 돌면서 Task scheduling 작업을 합니다. 반복되는 스케줄러 루프 과정은 아래와 같습니다.
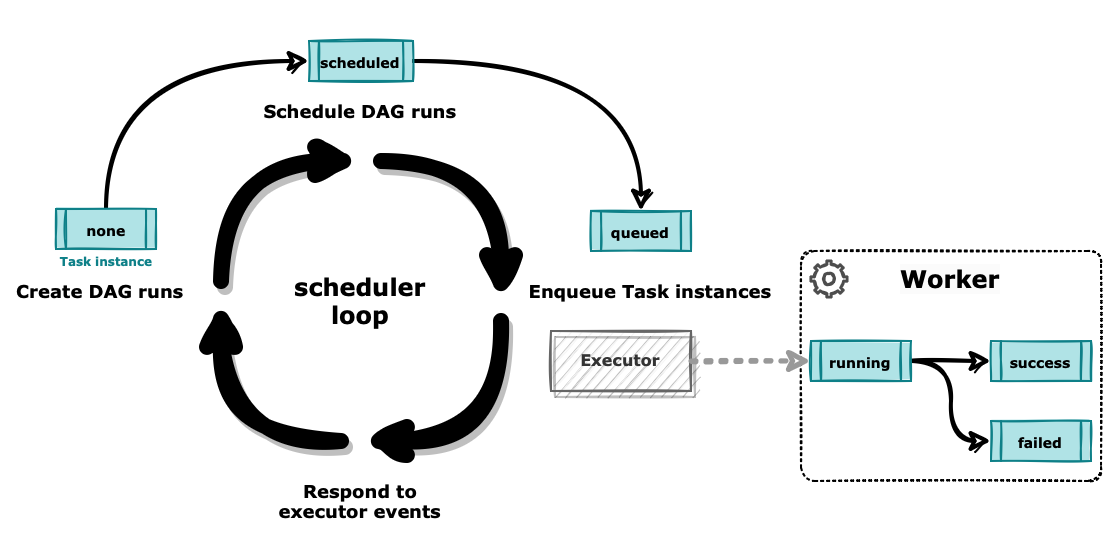
- ‘dag’ 테이블을 조회하여 실행 시점이 된 DAG를 가져와 DAG run [scheduled]과 Task instance [none]를 생성합니다.
- [scheduled] 상태의 DAG run을 가져와서 [running] 상태로 변경합니다.
- [running] 상태의 DAG run 중에서 실행 가능한 Task instance를 가져옵니다.
실행할 Task instance가 없거나 이슈가 발생한 DAG run은 상황에 따라 [success] 혹은 [failed] 상태로 변경합니다.
가져온 Task instance 들은 우선순위를 계산하여 [queued] 상태로 변경 후 executor 내부의 큐(queue)로 전달합니다.
큐는 파이썬 내장 객체
OrderedDict타입으로 되어있습니다. - Executor에서 큐에 있는 작업들을 차례로 워커에 전달합니다. 각 executor에 따라 작업 전달 방식은 조금씩 차이가 날 수 있습니다. 작업을 전달받은 워커는 Task 실행 후 경과에 따라 Task instance의 상태를 변경합니다.
- 일정 시간 sleep 후 위 작업을 계속 반복합니다.
4. Executor
Executor는 Task를 실행시키는 주체로 스케줄러 프로세스 내부에서 동작합니다. Airflow에서는 여러 executor를 제공하는데 각 executor 마다 작업 전달 방식 및 워커의 작동 방식도 조금씩 달라집니다.
- SequentialExecutor
- LocalExecutor
- CeleryExecutor
- KubernetesExecutor
- 등등…
4.1 SequentialExecutor
기본적으로 아무 세팅을 하지 않으면 SequentialExecutor로 설정됩니다.
메타 데이터베이스로 sqlite를 사용하고 있기 때문에 병렬 처리는 불가능합니다.
테스트 용도가 아니라면 해당 executor 사용은 권장하지 않고 있습니다.
4.2 LocalExecutor
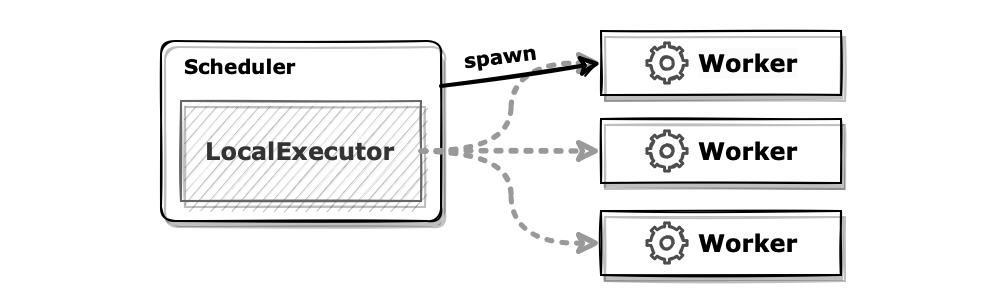
LocalExecutor는 병렬 처리가 가능한 기본적인 executor입니다.
메타 DB로 sqlite 대신 PostgreSQL, MySQL과 같이 멀티 커넥션이 가능한 데이터베이스를 사용해야 합니다.
워커 프로세스는 스케줄러의 서브 프로세스로 실행됩니다. parallelism 설정에 따라 미리 특정 숫자의 워커를 띄워두거나 혹은 작업 실행 시마다 워커 프로세스를 spawn 하는 방식으로 구성할 수 있습니다.
장점으로는 구성이 간편합니다. 단순히 기본 Airflow에서 메타 DB만 변경하면 바로 실행 가능합니다. 다만 워커가 스케줄러의 서브 프로세스로 실행되기 때문에 스케줄러와 워커가 반드시 동일한 인스턴스에 구성되어야 하므로 확장에 한계가 있습니다.
4.3 CeleryExecutor
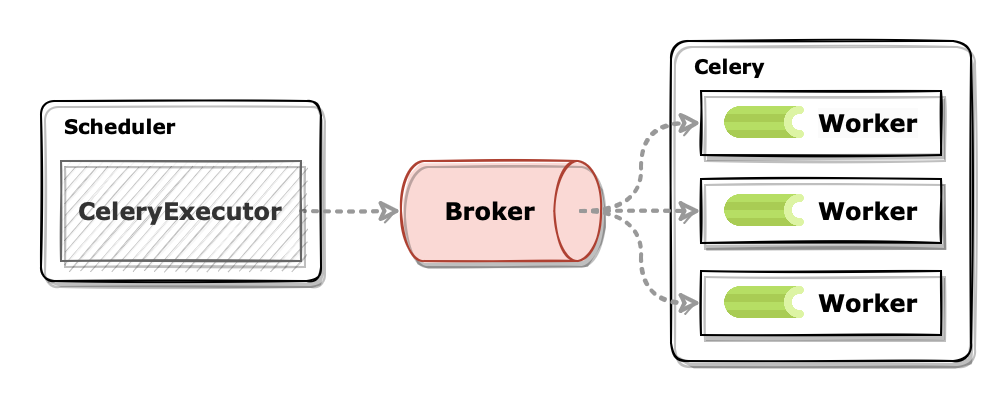
CeleryExecutor는 Celery를 도입한 executor입니다.
Celery 구성을 위해 message broker와 result backend가 추가적으로 필요합니다.
별도의 result backend 설정이 없으면 기본적으로 메타 DB를 사용하도록 되어있습니다.
Airflow의 워커가 아닌 Celery 워커를 이용하여 작업을 수행하므로 스케줄러와 별개로 직접 워커 프로세스를 실행해 주어야 합니다.
스케줄러는 작업을 대기열에 배치할 때 message broker를 이용합니다. 스케줄러가 broker에 실행되어야 할 Task의 정보를 전달하면 각 Celery 워커들은 broker로부터 메시지를 가져와서 알맞은 작업을 수행합니다.
작업에 대한 정보가 중간 broker를 통해 전달되는 구조라 확장이 매우 용이합니다. 인스턴스에 Celery 워커를 실행하여 동일하게 broker를 방식으로 확장이 가능합니다. 다만 추가적인 라이브러리나 서비스가 필요해서 구성하기 복잡합니다.
References
- Bas Harenslak & Julian de Ruiter, 『Data Pipeline with Apache Airflow』, 김정민 & 문선홍, 제이펍, 2022-03-16
- Core Concepts — Airflow Documentation
- DAG File Processing — Airflow Documentation
- 버킷플레이스 Airflow 도입기 - 오늘의집 블로그
- Kubernetes를 이용한 효율적인 데이터 엔지니어링(Airflow on Kubernetes VS Airflow Kubernetes Executor) - 1