
필자는 서버 개발자로 커리어를 이어가고 있지만 운이 좋게도 커리어 초반에 경력이 지긋한 이사님의 밀착 코칭을 받아 데이터베이스에 관해 전반적인 지식을 쌓을 수 있었습니다. 거쳐 간 회사들이 별도 DBA 직군이 존재하지 않아서 서버 개발자가 데이터베이스까지 관리해야 하는 환경이 오히려 다양한 경험을 쌓게 해주었다고 생각합니다. 어찌 보면 서버 개발자의 업무도 상당수가 데이터베이스에 대한 CRUD 작업이기에 데이터베이스의 특성을 숙지하고 있다면 업무에 많은 도움이 될 겁니다.
아래에 데이터베이스 구조에 대한 기본적인 내용을 정리하였습니다. 여기서는 오라클 위주로 설명하였지만, MySQL이나 PostgreSQL 등 대부분의 데이터베이스 시스템도 비슷한 원리로 동작합니다.
1. Table Space
데이터가 저장되는 큰 범주를 테이블 스페이스(Table Space)라고 합니다. 테이블 스페이스 안에는 세그먼트(Segment)라는 오브젝트가 존재하는데, 보통 테이블 데이터가 저장되는 데이터 세그먼트와 인덱스가 저장되는 인덱스 세그먼트로 구분됩니다. 일반적으로 한 테이블당 하나의 세그먼트로 이루어져 있으나, 만일 파티션 설정이 되어있다면 파티션마다 다른 세그먼트로 구성됩니다.
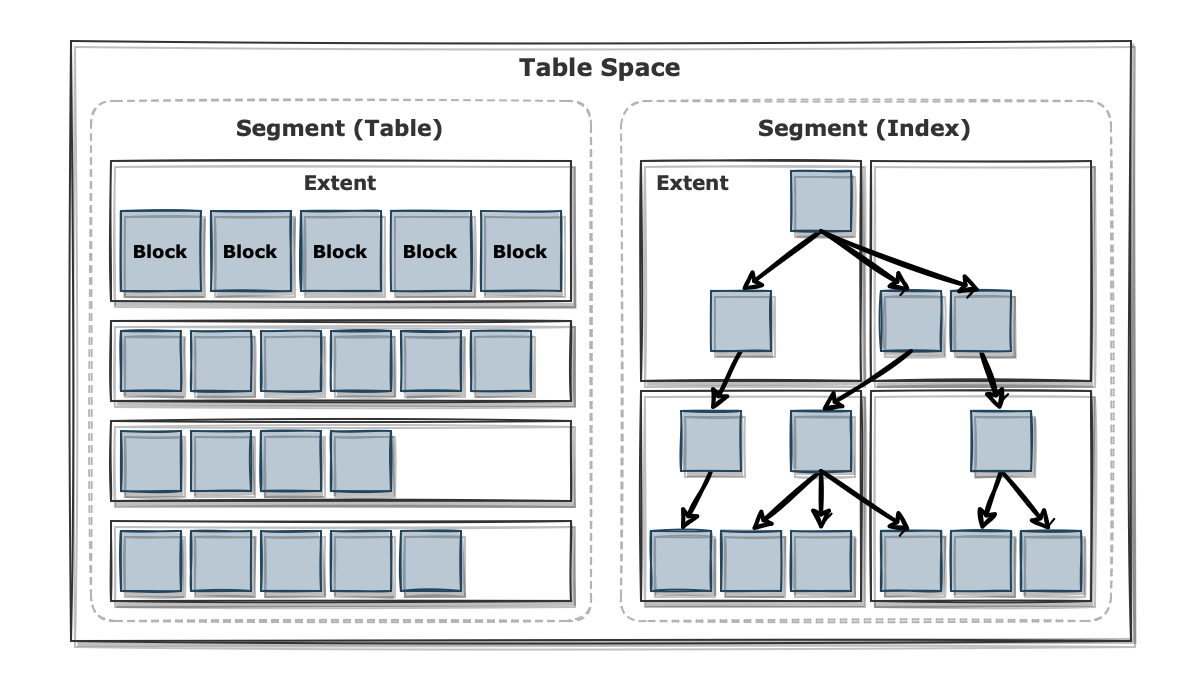
익스텐트(Extent)는 공간을 확장하는 단위입니다. 테이블에 데이터를 저장하다가 세그먼트 공간이 부족해지면 테이블 스페이스로부터 새로운 익스텐트를 할당받아 사용합니다. 그리고 실제로 데이터가 저장되는 공간은 익스텐트 내부의 블록(Block)입니다. 하나의 익스텐트 내에서 블록은 모두 인접한 연속 공간으로 존재합니다. 하지만 익스텐트끼리는 같은 세그먼트에 속해있더라도 연속되지 않을 수 있습니다.
블록은 DB로부터 데이터를 읽고 쓰는 단위입니다. 하나의 레코드를 읽는 경우에도 해당 블록 전체를 가져와 읽어야 합니다. 오라클에서는 기본적으로 8KB의 블록을 사용하는데, 1 Byte를 읽더라도 8KB 블록 전체를 가져와야 합니다.
💡 PostgreSQL에서도 동일하게 블록 단위로 데이터를 읽습니다. MySQL에서는 데이터를 읽는 최소 단위로 블록 대신 페이지(Page)라는 용어를 사용합니다. 기본적으로 PostgreSQL은 한 블록당 8KB, MySQL의 InnoDB 엔진은 한 페이지에 16KB의 공간을 할당합니다.
2. Memory
2.1 SGA
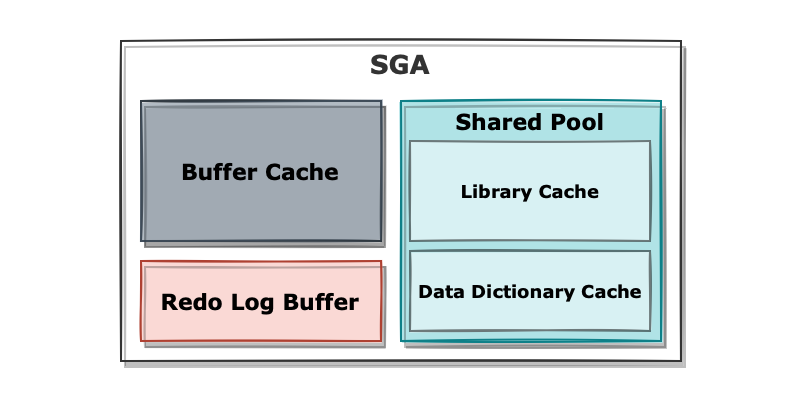
오라클은 SGA(System Global Area)라는 메모리 공간에서 서버 프로세스와 백그라운트 프로세스가 접근하는 데이터 및 제어 정보를 캐싱하고 있습니다. 데이터 블록을 캐싱하는 버퍼 캐시(Buffer Cache), 사용자가 실행한 쿼리를 저장하는 공유 풀(Shared Pool), 트랜잭션 로그를 기록하는 리두 로그 버퍼(Redo Log Buffer) 등으로 구성됩니다.
2.2 Buffer Cache
SQL의 성능을 좌지우지하는 건 바로 디스크 I/O 입니다. 앞서 데이터를 읽을 때 블록 단위로 가져와 읽는다고 했는데, 이 과정이 자주 반복될수록 성능이 떨어지게 됩니다. 이를 해결하기 위해 데이터베이스 메모리에 버퍼 캐시가 존재합니다. 데이터를 블록에서 직접 읽는 대신 메모리에 캐시 해두어 같은 블록에 대한 반복적인 접근을 방지하는 것을 목적으로 합니다.
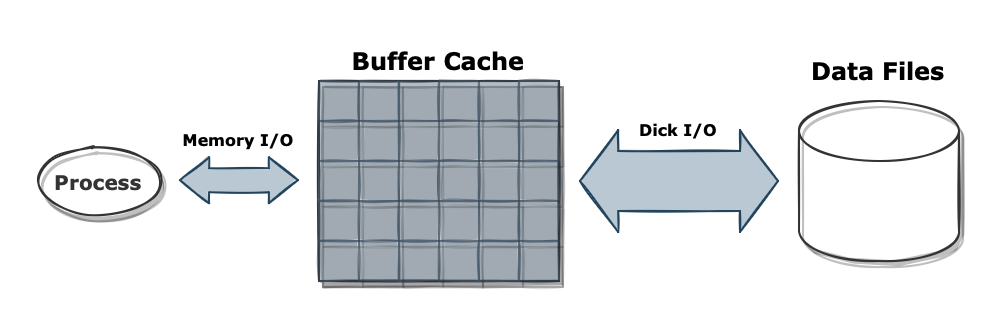
서버 프로세스는 항상 버퍼 캐시부터 스캔하여 데이터를 읽어갑니다. 만일 버퍼 캐시에서 데이터를 찾지 못했다면 디스크로 접근하여 해당하는 블록을 읽습니다. 이때 블록에 있는 데이터를 먼저 버퍼 캐시에 저장하고 읽게 되는데, 다음번 해당 블록을 읽을 때는 디스크에 접근할 필요 없이 버퍼 캐시에서 데이터를 읽어갈 수 있습니다. 일반적으로 메모리 I/O가 디스크 I/O보다 훨씬 가볍고 빠르기 때문이 이러한 메모리 캐싱을 통해 성능을 높일 수 있습니다.
2.3 Hit Rate
버퍼 캐시의 효율을 측정하는 지표로 Buffer Cache Hit Rate가 있습니다. 총 읽은 블록 개수 중 캐시에서 곧바로 찾은 블록 수의 비율로 계산하는데 해당 지표가 높을 수록 디스크에 접근하지 않고 메모리에서 데이터를 찾았다는 의미가 됩니다.
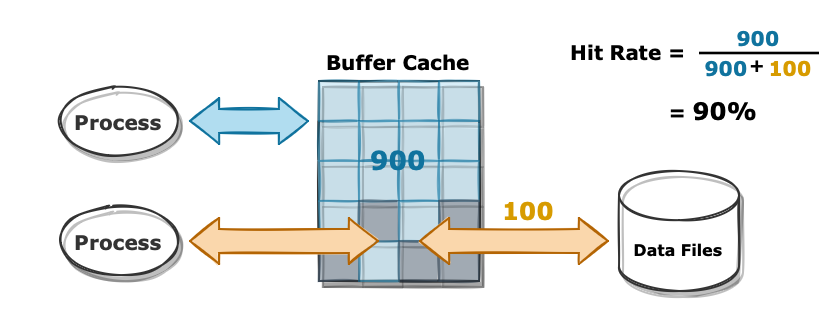
만일 1000개 블록을 읽었다고 가정했을 때 900개는 Buffer Cache에서 찾았고 100개는 디스크에서 가져왔다면 이때의 Hit Rate는 90%가 됩니다. 보통 일반적인 어플리케이션을 운영하는 경우에 Hit Rate 99% 정도를 권장하고 있습니다.
2.4 Latch
Buffer Cache에 캐시 된 블록들은 공유 자원입니다. 따라서 누구나 접근할 수 있기 때문에 Latch라는 메커니즘을 이용하여 여러 프로세스가 동시에 접근하지 않도록 제어해야 합니다.
Latch
3. Index
인덱스는 데이터를 정렬하여 데이터 검색 및 조회를 빠르게 하기 위한 핵심 요소입니다. 일반적으로 인덱스는 B-Tree 구조로 되어있습니다. 제일 상단에 Root 블록을 기준으로 가지가 되는 Branch 블록과 말단에 위치한 Leaf 블록으로 구성되어 있습니다.
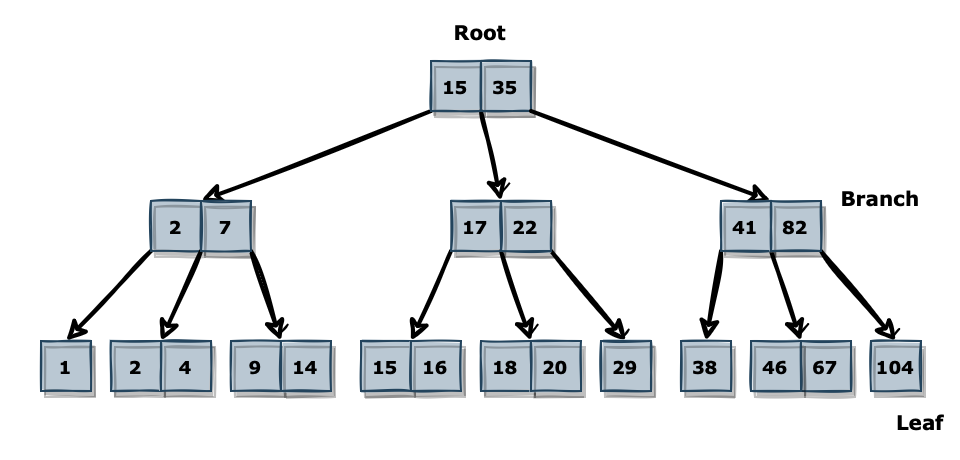
B-Tree 외에도 Hash, Bitmap 등을 사용하는 경우도 있지만, 아래 내용에서는 B-Tree 기준으로 설명하겠습니다.
3.1 Table Access
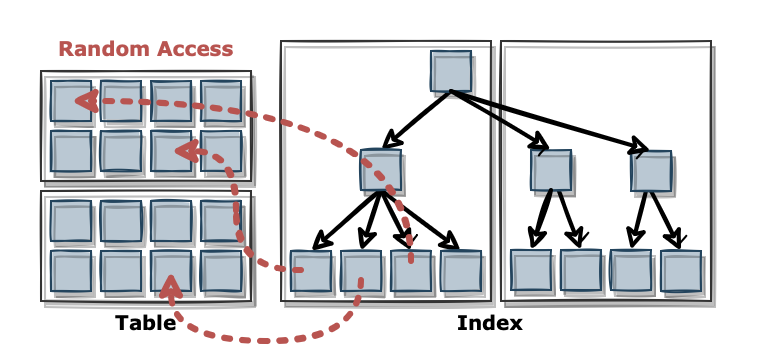
B-Tree의 말단에 위치한 Leaf 블록은 ROWID를 가지고 있습니다. ROWID는 데이터 블록의 주소값, row 번호 등을 포함하고 있는데 이 값으로 테이블 레코드에 바로 접근할 수 있습니다. 만일 찾는 컬럼 값이 인덱스에 모두 존재한다면 별도로 테이블에 접근하지 않고 해당 값을 읽어갑니다. 이렇게 블록을 하나씩 읽으며 레코드에 접근하는 방식을 Random Access라고 합니다.
인덱스의 블록을 읽는 과정에서도 해당 블록을 Buffer Cache에 저장해야 합니다. Root 블록에서부터 Branch, Leaf를 탐색할 때마다 먼저 Buffer Cache에서 해당 블록을 찾고 없는 경우에는 디스크에서 가져옵니다.
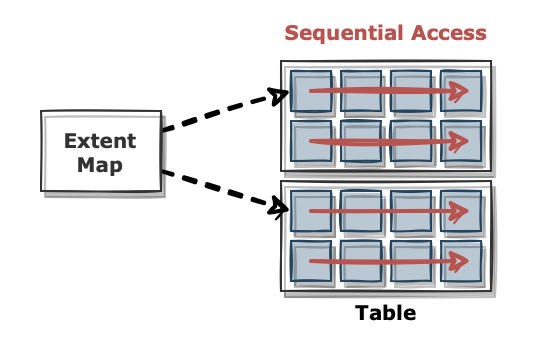
반대로 Sequential Access는 순서대로 블록을 읽는 방식입니다. 오라클에서는 세그먼트에 할당된 익스텐트의 첫 번째 블록의 주소값을 맵(map) 형태로 관리하고 있습니다. 하나의 익스텐트에서 블록은 인접해 있으므로 첫 번째 블록의 주소만 알아도 익스텐트 전체를 다 읽을 수 있습니다. 따라서 해당 익스텐트 맵에 등록된 익스텐트들을 차례로 읽다 보면 테이블 전체를 Full Scan 할 수 있습니다.
Sequential Access 과정에서도 먼저 Buffer Cache에서 데이터를 찾습니다. 하지만 Full Scan을 진행하면서 매번 디스크에서 블록을 하나씩만 가져오는 건 매우 비효율적입니다. 따라서 이때는 해당 블록이 속한 익스텐트의 블록들을 모두 Buffer Cache로 가져옵니다. 이러한 작업을 Multiblock I/O라고 하는데 한 번에 가져오는 블록이 많을수록 더 효율이 올라가게 됩니다.
3.2 Index Scan
인덱스로 데이터를 탐색하는 과정은 크게 수직적 탐색과 수평적 탐색으로 나눌 수 있습니다. 수직적 탐색은 인덱스 스캔의 시작 지점을 특정하는 과정이고, 수평적 탐색은 해당 지점부터 순차적으로 데이터를 가져오는 과정입니다.
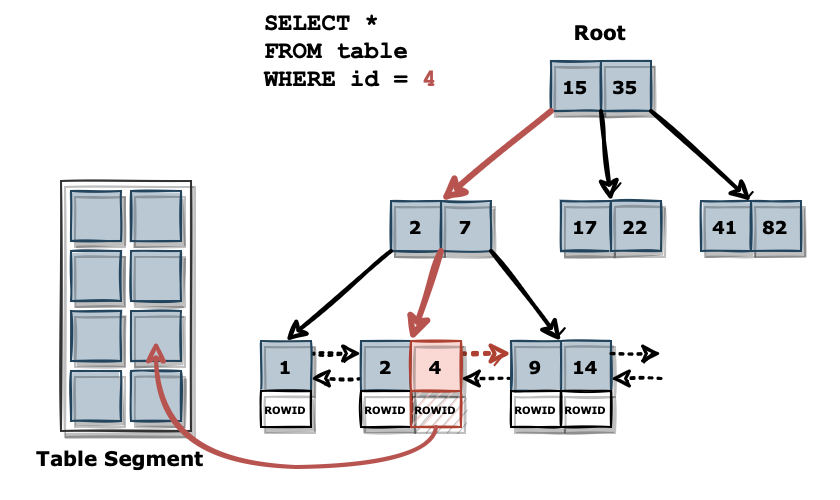
인덱스 스캔은 Root 블록에서 시작됩니다. Root 블록부터 하위 블록으로 내려가는데 키 값이 작거나 같으면 왼쪽으로, 크면 오른쪽으로 이동하여 Leaf 블록까지 도달합니다. 중간에 일치하는 블록을 만나도 조건에 맞는 Leaf 노드까지 탐색해야 합니다. 마지막에 도달한 Leaf 블록은 테이블 레코드를 스캔할 시작 지점이 됩니다.
시작 지점을 찾은 후에는 해당 블록부터 수평으로 데이터가 일치하는 범위를 찾습니다. B-Tree의 Leaf 블록끼리는 서로 앞뒤 블록의 주소값을 가지고 연결된 양방향 연결 리스트 구조입니다. 따라서 다음 블록으로 넘어가면서 원하는 값이 나오지 않을 때까지 스캔할 수 있습니다. 조건에 부합하는 블록을 모두 찾으면 해당 블록이 가지고 있는 ROWID로 원하는 레코드를 가져옵니다.
이러한 방식으로 인덱스를 이용하면 테이블을 Full Scan 하지 않고도 원하는 데이터를 바로 찾아갈 수 있습니다. 다만 인덱스는 소량의 데이터를 읽는 경우에 유리합니다. 만일 인덱스를 이용하여 다량의 데이터를 가져오려 한다면 Leaf 블록을 따라 수평적 탐색을 하면서 하나씩 블록을 읽어야 하는데, 이 과정은 Full Scan에서 Multiblock I/O를 이용하여 한 번에 여러 블록을 가져오는 방식에 비해서 비효율적입니다. 따라서 가져올 데이터 성격에 따라 적절한 탐색 방식을 사용해야 합니다.
References
- 조시형, 친절한 SQL 튜닝, 디비안, 2018-06-01
- MySQL :: MySQL 8.0 Reference Manual :: 15.11.2 File Space Management