
엘라스틱서치(elasticsearch)는 오픈소스 분산 검색 엔진입니다. 실시간으로 데이터를 입력하면서 동시에 저장된 데이터에 대한 검색 및 집계가 가능합니다. 초기에는 단순히 검색 엔진으로만 개발되었지만 현재는 ELK 스택과 시너지를 내면서 로그 모니터링 및 각종 분석 등으로 활용되고 있습니다.
1. Cluster & Node
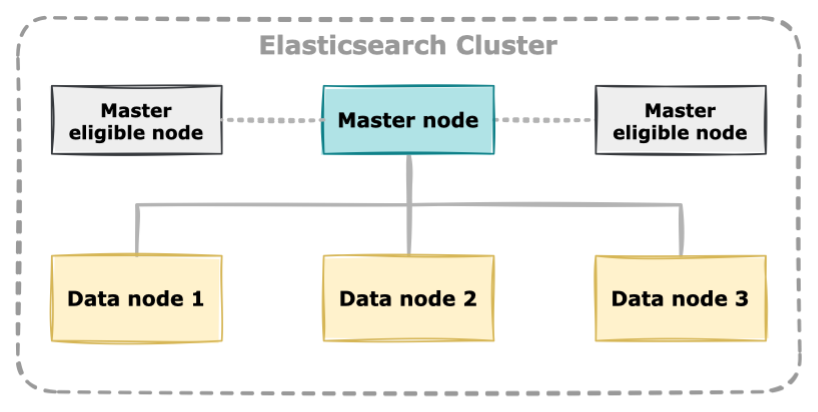
클러스터(cluster)라 함은 보통 여러대의 컴퓨터들을 묶어 마치 하나의 시스템처럼 유기적으로 동작하는 집합을 의미합니다. 엘라스틱서치도 기본적으로 저마다의 역할을 맡은 노드(node)들의 집합으로 이루어져 있습니다. 단일 노드로 구성하는 것도 가능하지만 프로덕션 레벨에서 운영하는 경우에는 안정성을 위해서 클러스터로 구성하는것을 권장합니다. 일반적으로는 한 인스턴스에 하나의 노드 세팅을 권장합니다.
각 노드마다 정해진 역할을 부여할 수 있습니다.
yml 파일에서 node.roles 값을 이용하여 설정할 수 있습니다.
노드의 역할은 약 12가지가 있지만 그 중 많이 사용하는 두 가지만 살펴봅시다.
-
마스터 노드 마스터 노드는 클러스터를 전체를 관리하는 역할을 합니다. 인덱스의 메타 데이터, 샤드의 위치와 같은 정보를 체크합니다. 클러스터에는 반드시 하나의 마스터 노드가 존재해야 합니다. 노드에
node.roles=['master']값을 설정하면 마스터 선출 후보 노드(master eligible node) 역할을 부여받는데, 해당 노드 중 하나의 노드만이 마스터 노드의 역할을 수행합니다. 나머지 후보 노드들은 마스터 노드에 장애가 생기는 경우를 대비하여 마스터 노드와 정보를 공유합니다. -
데이터 노드 데이터 노드는 실제로 데이터를 저장하는 곳입니다. 데이터 CRUD, 검색, 집계 등의 작업이 빈번하게 이루어지기 때문에 디스크 I/O, CPU, 메모리와 같은 자원이 충분해야 합니다. 데이터 노드는
node.roles=['data']으로 설정이 가능합니다.
이 외에도 ingest 노드, ml 노드 등이 있습니다.
노드는 9200~9299번 포트를 이용하여 클라이언트와 통신하고 노드 간에는 9300~9399번 포트를 이용하셔 통신합니다.
또한 클러스터를 구성하는 노드는 동일한 cluster.name 을 설정해야 합니다.
초기 실행 시 discovery.seed_hosts 에 설정된 노드와 통신을 하는데 만일 cluster.name 이 일치하지 않는 경우 클러스터를 구성하지 않고 독자적으로 클러스터를 구성하게 됩니다.
2. Index & Shard
인덱스(index)는 데이터가 저장되는 물리적인 공간입니다. 일반적인 RBD의 테이블과 비슷한 개념이라고 할 수 있습니다. 인덱스에 저장되는 데이터를 Document라고 하는데 저장될 때 색인(indexing)이라는 가공 과정을 거칩니다.
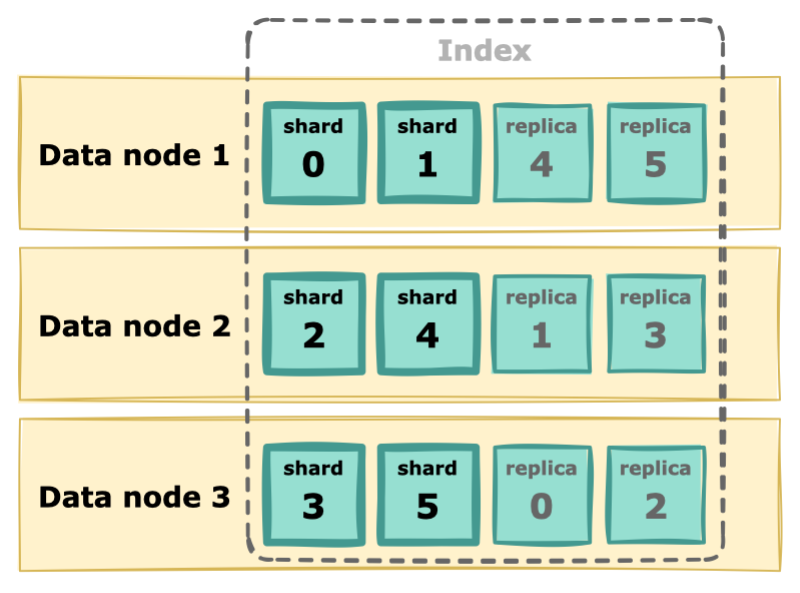
엘라스틱서치가 인덱스에 데이터를 저장할 때 한 곳에 저장하지 않고 샤드(shard)에 나누어 저장합니다. 또한 원본과 복제본을 나누어 저장하는데, 원본 document가 저장되는 샤드는 primary shard 이고 복제본이 저장되는 샤드는 replica shard 입니다. 이때, replica shard 는 primary shard 와는 다른 노드에 저장됩니다. 따라서 단일 노드로만 구성된 경우에는 replica 를 설정할 수 없습니다.
만약 한 인덱스를 3개의 데이터 노드에 primary shard 6개, replica shard 1개로 구성하는 경우 각 노드에 두 개의 primary shard가 생성되고 또 각 샤드마다 1개의 복제본을 생성하여 총 6개의 replica가 각 노드에 분배되어 구성됩니다.
3. Field
인덱스에 저장되는 document에 대하여 각 필드(field)를 정의할 수 있습니다.
일반적인 RDB의 테이블과 같이 integer, date, boolean 같은 타입을 지원합니다.
다만 같은 string이지만 text와 keyword는 서로 다른 방식으로 작동합니다.
-
text 텍스트를 필드 혹은 인덱스에 정의된 analyzer 에 따라 토큰으로 쪼개어 저장합니다. 기본적으로 띄어쓰기만으로 구분해주는 standard analyzer가 적용되어 있습니다. 검색에 사용되어야 하는 필드에 주로 사용합니다.
-
keyword 입력받은 텍스트 전체를 하나의 토큰으로 저장합니다. 검색에 쓰이지 않는 데이터는 보통 keyword 로 설정하여 불필요한 형태소 분석 과정을 줄입니다.
References