
보통 구글 혹은 네이버 검색창을 보면 키보드로 입력할 때마다 연관된 키워드가 나타나는 것을 확인할 수 있습니다. 굳이 사이트 뿐 아니라 검색 기능을 제공하는 웬만한 모바일 앱에서도 이러한 자동완성 기능을 제공하고 있습니다.
자동완성 API는 문자 하나를 입력할 때마다 반영되어야 하므로 빠른 성능이 요구됩니다. 따라서 일반적인 RDB보다는 검색에 최적화된 엘라스틱서치를 활용할 수 있습니다.
1. N-Gram
본래 N-Gram 언어 모델이라고 하면 텍스트를 단어 또는 음절 단위로 분리해서 각 단위를 기반으로 문맥을 이해하고 다음 단어를 예측하는 모델을 말합니다. 일반적으로 띄어쓰기를 기준으로 문장을 분리하는데, 1개 단어씩 끊은 unigram, 2개씩 분리한 bigram 등 여러 단위로 설정하여 모델을 설계할 수 있습니다. 일례로 ‘I like watching movies’ 라는 문장은 각 모델에 따라 아래와 같이 구분할 수 있습니다.
| Models | Terms |
|---|---|
| unigram (N=1) | I / like / watching / movies |
| bigram (N=2) | I like / like watching / watching movies |
| trigram (N=3) | I like watching / like watching movies |
1.1 N-Gram Tokenizer
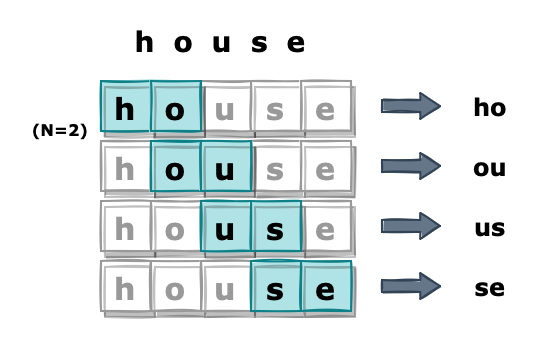
엘라스틱서치의 N-Gram 토크나이저도 해당 개념에서 차용했습니다. 대신 입력받은 단어를 문장을 띄어쓰기가 아닌 특정 길이(N)의 문자열로 쪼갭니다. 만일 N=2인 경우 ‘house’ 라는 단어는 ‘ho’, ‘ou’, ‘us’, ‘se’ 네 개의 토큰으로 나눌 수 있습니다.
GET /_analyze
{
"tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 2
},
"text": "house"
}
# Response
{
"tokens" : [
{
"token" : "ho",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "ou",
"start_offset" : 1,
"end_offset" : 3,
"type" : "word",
"position" : 1
},
{
"token" : "us",
"start_offset" : 2,
"end_offset" : 4,
"type" : "word",
"position" : 2
},
{
"token" : "se",
"start_offset" : 3,
"end_offset" : 5,
"type" : "word",
"position" : 3
}
]
}
쪼개진 토큰은 역인덱스 구조에 저장되어 검색 시에 사용됩니다. 만약 해당 토크나이저로 문서를 색인하였다면 ‘ho’로 검색해도 ‘house’가 포함된 문서를 가져올 수 있습니다.
N-Gram 토크나이저는 min_gram, max_gram 인자를 이용하여 여러 N 값을 조정할 수 있습니다.
하지만 다양한 N을 설정할수록 저장되는 토큰의 개수가 기하급수적으로 많아지기 때문에 성능을 고려하여 적절한 수치로 조정해야 합니다.
1.2 Edge N-Gram Tokenizer
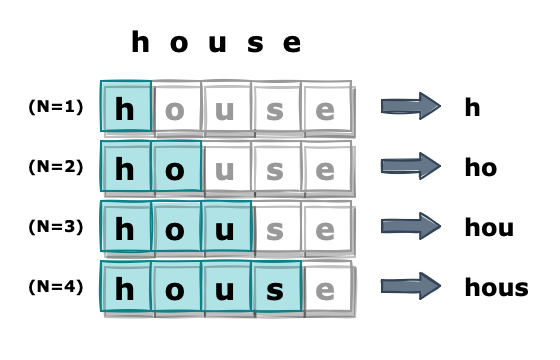
일반적으로 검색할 때는 단어를 앞에서부터 입력하게 됩니다. 그리고 자동완성 키워드는 주로 입력한 문자열로 시작하는 키워드를 가져오게 됩니다. 예를 들어 ‘house’라는 단어를 검색하는 경우 ‘h’, ‘ho’ 순으로 입력하며 이때, 노출되는 자동완성 키워드는 ‘h’ 또는 ‘ho’로 시작하는 문자열이 대상이 됩니다.
이 말인즉슨 N-Gram으로 생성한 ‘ou’, ‘us’, ‘se’와 같은 토큰은 그다지 큰 효용성이 없고, 오히려 ‘h’, ‘ho’, ‘hou’와 같이 쪼개는 방법이 더 효율적일 수 있다는 의미이기도 합니다.
이러한 방식으로 토큰을 구분하기 위해 Edge N-Gram 토크나이저를 사용할 수 있습니다. Edge N-Gram은 N-Gram과 유사하게 입력받은 텍스트를 길이 N의 문자열로 분리하지만, 대신 앞에서부터 연속한 N개의 문자열만 가져옵니다.
GET /_analyze
{
"tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 4
},
"text": "house"
}
# Response
{
"tokens" : [
{
"token" : "h",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "ho",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 1
},
{
"token" : "hou",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 2
},
{
"token" : "hous",
"start_offset" : 0,
"end_offset" : 4,
"type" : "word",
"position" : 3
}
]
}
해당 토크나이저도 min_gram, max_gram 파라미터로 다양한 N 값을 설정할 수 있습니다.
Edge N-Gram을 사용하여 문자열을 처리하면 하나의 N에 대해서 생성되는 토큰의 경우의 수가 N-Gram에 비해 훨씬 줄어듭니다. 따라서 굳이 문자열의 모든 위치에서 부분 일치를 찾을 필요가 없는 자동완성 모델에서 많이 사용됩니다.
2. 자소 분리
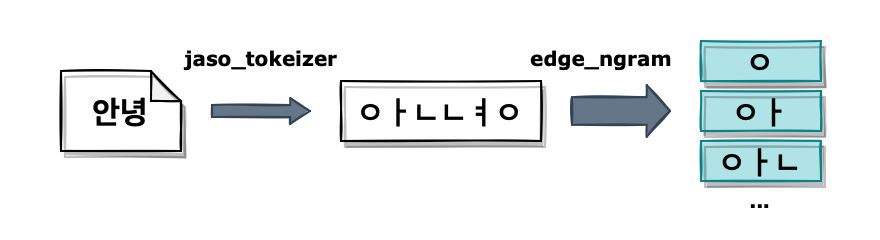
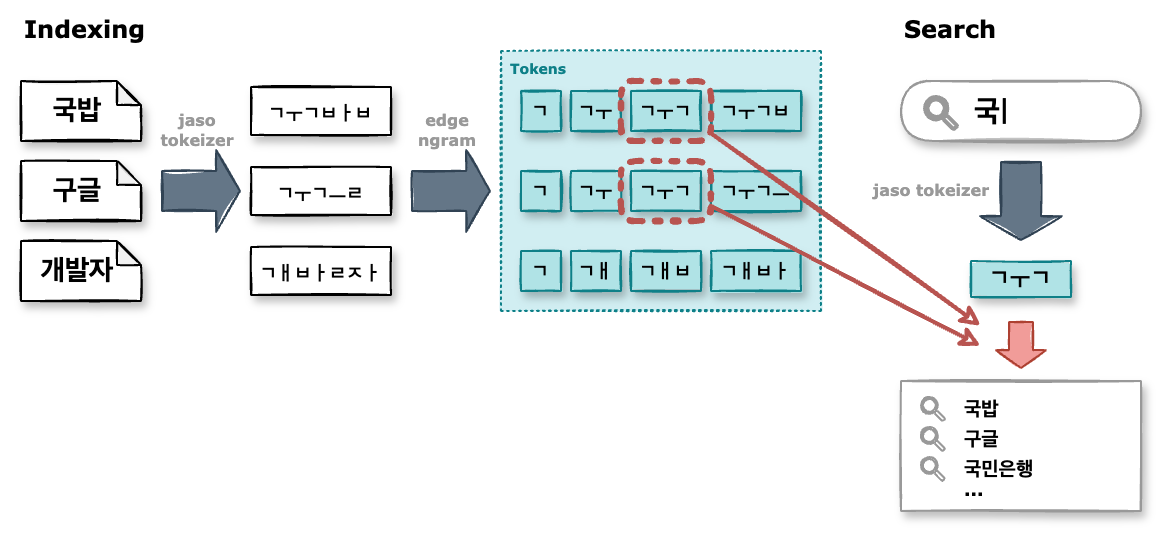
보통 한글 단어를 검색하는 경우 자동완성 키워드는 자음, 모음 하나씩 입력할 때마다 반영됩니다. 또한 ‘국’ 이라는 단어를 입력했을 때 ‘국밥’, ‘구글’ 둘 다 대상이 될 수 있습니다. 그 원리를 분석해 보면 ‘국’이라는 글자를 ‘ㄱㅜㄱ’으로 분리했을 때 마지막 ㄱ이 초성이 될 수도 있고 종성이 될 수도 있기 때문입니다.
이처럼 자동완성 모델에서 한글 문자의 자음/모음을 분리하는 작업은 꼭 필요합니다. 해당 기능은 엘라스틱서치에 내장되지 않았지만 외부 플러그인을 사용할 수 있습니다. 여기서는 elasticsearch-jaso-analyzer를 사용하겠습니다. 설치하는 방법은 해당 페이지에 나와 있으니 생략하겠습니다.
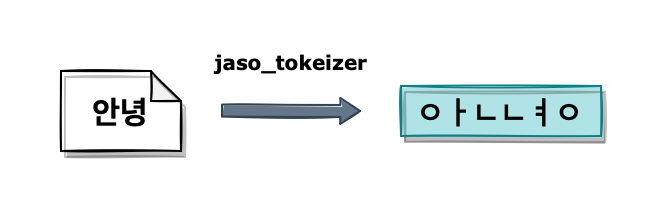
설치가 끝나면 jaso_tokenizer를 사용할 수 있습니다.
‘안녕하세요’라는 문자열을 처리해 보면 아래와 같이 자음과 모음이 분리된 토큰을 확인할 수 있습니다.
GET /_analyze
{
"tokenizer": "jaso_tokenizer",
"text": "안녕하세요"
}
# Response
{
"tokens" : [
{
"token" : "ㅇㅏㄴㄴㅕㅇㅎㅏㅅㅔㅇㅛ",
"start_offset" : 0,
"end_offset" : 12,
"type" : "word",
"position" : 0
}
]
}
3. 모델 설계
위 내용을 종합하여 자동완성 모델을 설계하려고 합니다. 다음과 같은 인덱스를 생성하였습니다.
PUT /autocomplete-keyword
{
"settings": {
"analysis": {
"filter": {
"f_ngram_autocmpl": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 50
}
},
"analyzer": {
"a_autocmpl_index": {
"tokenizer": "jaso_tokenizer",
"filter": ["f_ngram_autocmpl"]
},
"a_autocmpl_search": {
"tokenizer": "jaso_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"word": {
"type": "text",
"analyzer": "a_autocmpl_index",
"search_analyzer": "a_autocmpl_search"
}
}
}
}
자동완성에만 사용된 인덱스이므로 키워드를 저장할 word 필드 하나만 설정하였습니다.
해당 필드는 text 타입으로 설정하였고 색인용 & 검색용 두 개의 analyzer를 정의하였습니다.
a_autocmpl_index analyzer는 문서 저장 시 색인에 사용하였습니다.
먼저 토크나이저가 입력받은 문자열의 자음/모음을 분리하며, 토큰 필터에서 Edge N-Gram이 문자열을 구분합니다.
Edge N-Gram의 최대 N값은 50으로 설정해 두었습니다.
a_autocmpl_search analyzer는 검색 시에 적용됩니다.
보통 별다른 설정이 없으면 검색 시에도 색인할 때 설정한 analyzer를 이용하지만, text 필드에 search_analyzer를 설정하면 검색할 때 해당 analyzer를 사용하게 됩니다.
검색할때는 별도 N-Gram 설정 없이 자음/모음만 분리하도록 하였습니다.
검색 쿼리는 아래와 같이 설정하였습니다.
GET /autocomplete-keyword/_search
{
"size": 10,
"query": {
"match": {
"word": 입력한키워드
}
}
}
word 필드에서 매칭되는 키워드를 가져오도록 하였습니다.
검색 결과는 score 기준으로 상위 10개만 조회하였습니다.
4. Autocomplete
자동완성 프로세스를 정리하면 아래와 같습니다.
생성한 인덱스에는 결과로 반환할 키워드가 미리 입력되어 있어야 합니다.
해당 키워드는 입력될 때마다 필드에 설정된 analyzer에 의해서 자/모음이 분해된 여러 토큰으로 나누어지고 역인덱스 구조에 저장됩니다.
그리고 검색 시에 사용자가 입력한 문자는 search_analyzer가 처리하여 자/모음이 분해된 토큰으로 변환됩니다.
이때 역인덱스 구조에서 일치하는 토큰을 찾아서 해당 토큰이 포함된 키워드를 가져옵니다.
GET /autocomplete-keyword/_search
{
"size": 10,
"query": {
"match": {
"word": "국"
}
}
}
# Response
{
"took" : 17,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 22,
"relation" : "eq"
},
"max_score" : 6.436837,
"hits" : [
{
"_index" : "autocomplete-keyword",
"_type" : "_doc",
"_id" : "3KuJ4owB-auK4eYlxmNH",
"_score" : 6.436837,
"_source" : {
"word" : "국밥"
}
},
{
"_index" : "autocomplete-keyword",
"_type" : "_doc",
"_id" : "8KuJ4owB-auK4eYl3GMs",
"_score" : 6.436837,
"_source" : {
"word" : "구글"
}
},
...
5. Conclusion
자동완성 기능은 사용자가 문자를 입력할 때마다 빠른 응답이 요구되기 때문에 성능 최적화가 중요합니다. 따라서 복잡한 작업은 가능하다면 검색보다는 색인 시에 처리하는 것이 좀 더 효율적입니다. 위 모델에서 N-Gram으로 최대 50개의 토큰을 생성한 것과 같이 데이터 처리가 필요한 부분을 미리 처리해 두면 검색 시점에서는 이미 전처리가 된 데이터를 빠르게 검색할 수 있습니다.
References
- [NLP] N-gram 언어 모델의 개념, 종류, 한계점
- 6.6.4 NGram, Edge NGram, Shingle - Elastic 가이드북
- GitHub - netcrazy/elasticsearch-jaso-analyzer
- [Elastic] 2. Elastic 자동완성 가이드 (Autocomplete Guide) - Index Search | renuevo blog