
해당 포스트는 Meta 블로그의 Python Lazy Imports With Cinder 포스트를 번역한 글입니다.
게시일: 2022.06.15
Cinder의 Lazy Import
파이썬은 별도 컴파일 과정 없이 빠른 코드 수정 및 실행이 가능하다는 장점 덕분에 개발자 친화적인 언어로 널리 사용되고 있습니다. 하지만 대규모로 운영되는 인스타그램 서버를 로컬 개발 환경에 구성하는 경우 이러한 사용성 이점을 제대로 누리지 못하고 있었습니다. 파이썬 코드를 변경한 후 로컬 환경에서 서버를 재시작하면 이 과정에서 서버 시작 시간이 지연되어 평균적으로 50초가량 소요된다는 점이 주요 골칫거리였습니다.
메타에서는 Lazy Imports 기능을 도입하여 이러한 문제를 해결하였습니다. Lazy Imports는 lazy loading에 명확하고도 강력한 메커니즘을 접목시킨 파이썬 런타임 기능인데, 이러한 방식으로 서버 재시작 시간을 70% 절감하여 매일마다 개발자들의 수백 시간을 절약하고 있습니다.
식어버린 커피
아침이 밝았습니다. 당신은 눈을 뜨자마자 따뜻한 커피 한 잔을 들고 컴퓨터 앞으로 향했습니다. 당신의 머리속에는 오늘 업무에 대한 무궁무진한 아이디어가 넘쳐납니다. 커피 한 모금을 마신 후 코드를 리베이스하고 로컬 서버를 실행합니다. 하루 일과가 시작되었습니다!
평소처럼 몇몇 파일을 건드렸고 서버를 다시 시작했습니다.
서버가 완전히 시작되기까지 어느 정도 시간이 소요됩니다.
서버가 잘 돌아가는 듯 싶더니.. 잠시 후 에러가 발생하였습니다.
그중 일부는 어디서 발생했는지조차 가늠이 되지 않아서 traceback을 확인하고자 몇몇 파일에 로깅을 추가했습니다.
다시 10초, 20초.., 60초가 지나갔지만, 여전히 서버는 재시작 중입니다.
그리고 또다시 에러가 발생했는데 추가했던 로깅 라인에 구문 에러가 포함되어 있었습니다.
에러를 수정한 후 서버를 재시작했고 또다시 하염없는 기다림이 시작되었습니다.
2분여가 지나고 나서야 에러 로그를 확인할 수 있었으며, 한 시간 후에는 버그를 고칠 수 있었습니다.
원인은 바로 이틀 전 제거한 import 구문이었는데 아침에 최신 코드를 리베이스하면서 불러오는 모듈이 꼬여버린 것이었습니다.
이 과정에서 소중한 아침 두 시간을 낭비했고 오늘 해야 할 일을 전혀 진행하지 못했습니다. 더군다나 아까 가져온 따끈한 커피는 이미 차게 식어버렸습니다.
이렇게 서버를 기다리는 시간이 하루 종일 쌓이게 되고 마찬가지로 다른 동료들도 동일한 문제를 겪게 됩니다. 그렇게 누적된 시간은 몇 시간, 며칠이 되어 결국 어마어마한 시간 낭비가 발생하고 있습니다.
느려터진 서버 재시작
인스타그램 서버를 구동할 때마다 모듈을 불러오는 데 어마어마한 시간이 소요됩니다. 어떤 경우에는 모듈끼리 밀접하게 연계되어 있어서 하나의 모듈을 불러오더라도 엮인 모듈들을 연쇄적으로 가져오게 되기도 합니다.
서버 재시작 시간은 2021년도 말에 약 25초 정도 소요되었습니다. 이 소요 시간은 수년간 골칫거리로 과거부터 지속적으로 늘어나고 있었습니다. 개발자들이 꾸준하게 최적화 해주지 않으면 시간은 급격하게 치솟았고 결국 2021년 신기록을 달성해 버렸습니다. 2021년 끝물에 최고점을 찍었을 때는 1분 30초까지 소요된 적이 있었습니다. 이렇게 느려터진 서버를 기다리는 동안 엔지니어의 집중력이 흐려지고 하려던 일을 까먹을 모습이 불 보듯 뻔했습니다.
그렇다면 왜 이렇게 서버가 느려진 걸까요?
코드베이스 복잡성
이렇게까지 서버 시작 시간이 느려진 주요한 요인은 바로 인스타그램의 코드베이스 복잡성 증가와 코드가 참조하고 있는 수많은 모듈 때문입니다.
Joshua Lear는 하루 온 종일을 쏟아부어서 이전까지 아무도 보지 못했던 인스타그램 서버 코드의 복잡한 의존성 그래프를 만들었습니다. 의존성 그래프를 시각화하는 스크립트를 약 3시간 정도 실행한 후 “거대한 검은 점” 하나가 출력되었습니다. 처음 그래프를 확인했을 때는 버그가 발생한 줄 알았지만 이내 인스타그램의 의존성이 이렇게 거대하다는 사실을 깨달았습니다.
 Joshua Lear의 인스타그램 의존성 그래프 (예술적 재창조)
Joshua Lear의 인스타그램 의존성 그래프 (예술적 재창조)
실제로 인스타그램의 코드베이스 의존성은 모든 부분이 강하게 연결되어 있어서 마치 거대한 그물망과 같이 되어있습니다. 그래서 서버를 시작하는 것만으로도 약 28,000개의 모듈을 불러오게 되는데, 이 부분에서 모듈을 가져와 파이썬 함수 및 클래스 객체를 생성하는 데 상당한 시간이 소요됩니다. 좀 더 봐줄 만한 의존성 그래프는 Benjamin Woodruff가 현재 상태를 반영하여 다시 만들었고 그 결과물은 아래와 같습니다.
 현 시점 인스타그램 의존성 그래프, January 2022
현 시점 인스타그램 의존성 그래프, January 2022
그러면 과연 무엇이 문제였을까요? 코드에서 의존성이 심한 부분을 찾아서 제거해 주기만 하면 되는 걸가요? 이게 그렇게 간단하지만은 않습니다.
순환 참조
복잡한 코드와 강하게 얽힌 의존성은 재앙과도 같습니다. 의존성을 덜어내기 위해서 코드 리팩토링이 최선의 방법으로 여겨지지만 가장 큰 걸림돌은 바로 순환 참조입니다. 리팩토링을 시도하는 순간 사방에서 순환 참조가 발생할 수 있습니다.
순환 참조는 리팩토링을 까다롭게 만들고 이전에도 여러 장애를 일으켰습니다. 심지어 import 순서를 바꾸는 것조차도 순환 참조를 유발할 수 있습니다.
한 줄기 빛
우리는 이전에 순환 참조를 걷어내고 의존성을 간결하게 하기 위해 모듈 리팩토링을 진행한 적이 있었습니다. 당시 Django Url, Notifications, Observers, 정규식 등과 같은 무거운 하위 시스템을 지연시키면서 신중하게 솔루션을 조정하였습니다. 이러한 작업은 어느 정도 효과가 있었지만 대신 많이 불안정했습니다. 수년 동안 수많은 시간을 쏟아부어 일일이 프로파일링하고 리팩토링하며 정리 작업을 진행했음에도 불구하고 코드 복잡성이 지속적으로 증가하면서 공들인 노력이 다시 수포로 돌아갔습니다. 이러한 리팩토링 과정은 너무 힘겨웠고, 불안정했으며, 확장성이 좋지도 않았습니다.
우리가 원했던 건 모든 걸 느긋하게 만들 강력한 방법이었습니다.
Lazy Imports
 Creative Commons의 Geoff Gallice로부터 제공받은 두발가락나무늘보
Creative Commons의 Geoff Gallice로부터 제공받은 두발가락나무늘보
우리는 좀 더 깔끔하고 손이 많이 가지 않으면서도 신뢰성 높고 영구적인 방법으로 모듈을 가져오는 시점을 늦출 방법이 필요했습니다.
더 이상 메소드 내부에서 import 호출을 하거나 import_module(), __import__() 를 사용하는 방식은 피하고 싶었습니다.
구상하고 있는 프로젝트는 야심 차고 위험했지만 저는 소매를 걷어붙이고 CPython를 파고들어 Cinder 내부에 Lazy Imports를 구현하기 시작했습니다.
Lazy Imports는 파이썬이 모듈을 불러오는 메커니즘을 바꾸어 모듈이 사용되는 시점에만 가져오도록 하였습니다. 구체적으로 매 import 호출 라인마다 즉시 모듈을 로드하지 않고 대신 “지연 객체” 이름을 생성합니다. 그 이름은 사용되기 전까지 지연 객체의 인스턴스로 남아있게 됩니다. 그리고 곧바로 다음 라인에서 사용되거나 혹은 몇 시간 후에 콜 스택에서 사용될 수도 있습니다.
몇 주 동안의 작업을 거친 끝에 프로토타입을 만들 수 있었습니다. 결과는 성공적이었습니다. 원하는 대로 잘 작동했으며 몹시 기대되었습니다. 하지만 앞으로 펼쳐질 험난한 싸움은 미처 생각하지 못했습니다. 힘들었던 부분은 이 구현체를 좀 더 견고하게 만들고 효율적으로 구성하며 안정적으로 배포되도록 하는 것이었습니다. 무엇보다도 이 기능을 위해 파이썬 핵심 부분을 변경하는건 제가 처음 예상한 것보다 훨씬 더 복잡한 과정이었습니다. 그리고 작업 도중에서야 발견하고 손대야 했던 수많은 난관이 있었습니다.
파이썬의 내부 동작 방식에 많은 변덕과 미묘한 차이가 존재하며, Lazy Imports에서 지연 객체 개념은 C언어에서 파이썬으로 넘어왔습니다. Carl Meyer, Dino Viehland와 충분한 논의를 가진 끝에 저는 대부분의 기능을 파이썬 핵심부, 즉 파이썬 dictionary 내부로 옮기는 방식으로 다시 설계하기로 결정했습니다. 저는 무척이나 신났지만, 고도로 최적화된 dictionary 구현체를 자칫 잘못 건드렸다가는 심각한 성능 하락으로 이어질 수 있기 때문에 이 최적화 작업에 굉장히 심혈을 기울였습니다.
마침내 믿을만하고 효율적인 버전을 만들었습니다. 저는 수만 개의 인스타그램 서버 모듈에 Lazy Imports를 작동시켰고 성능 테스트를 진행하여 과연 운영 환경에서 성능 차이가 발생하지 않을지 확인하였습니다. 아니나 다를까 성능적으로 큰 변화가 없었고 운영 환경에서 어떠한 부정적인 양상도 발견되지 않았습니다.
결과
2022년 1월에 해당 기능을 수천 개의 개발 & 운영 환경에 문제없이 배포했고 곧바로 그래프에서 인스타그램 서버의 재시작 시간 차이를 확인할 수 있었습니다.
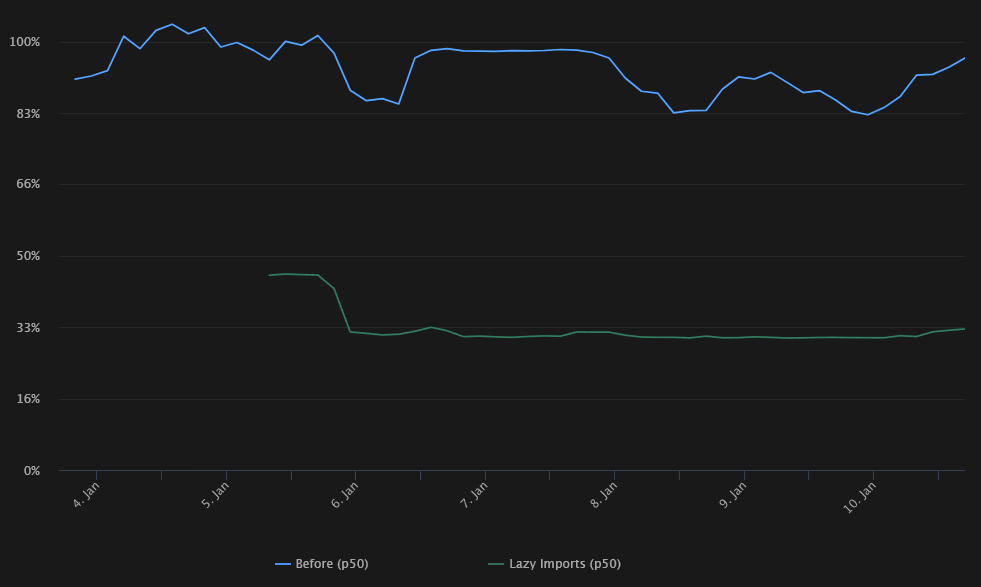
모듈을 12배 적게 로드하면서 개발 서버의 평균 재시작 시간의 중앙값은 70% 줄어들었고 90th percentile 값은 60% 감소하였습니다. 동시에 우리가 매일 신경 쓰던 순환 참조 에러도 사실상 모두 제거되었습니다. 인스타그램 외의 다른 서버에서도 동일하게 50~70% 성능이 향상되었고 메모리 사용량은 20~40% 까지 감소했습니다.
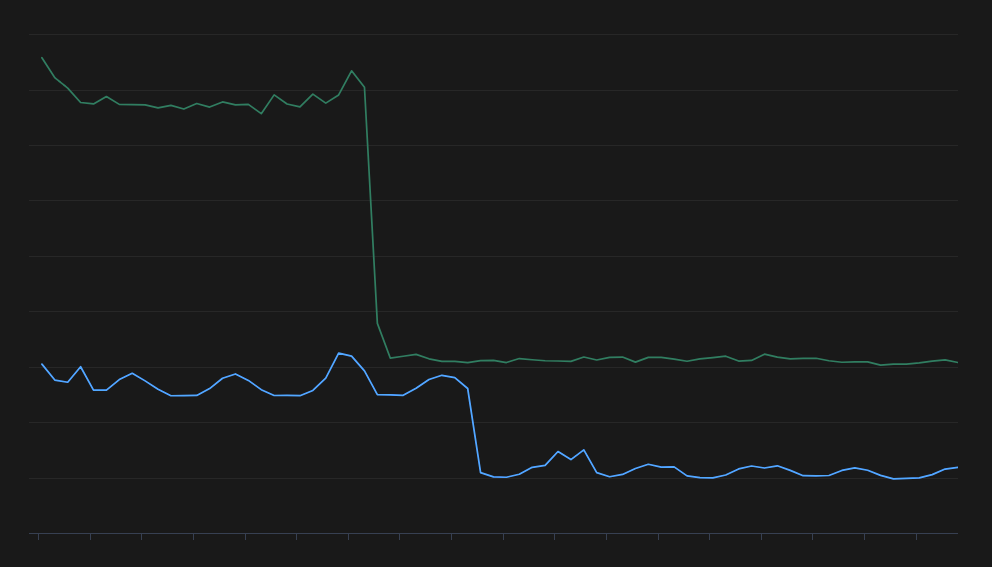 그래프의 어느 지점에서 Lazy Imports가 반영되었는지 보이시나요?
그래프의 어느 지점에서 Lazy Imports가 반영되었는지 보이시나요?
추가적인 결과는 여기를 참고해 주세요.
시행착오
프로젝트를 진행하면서 여기 포스트에는 담지 못할 수많은 난관이 있었습니다.
중간중간 매우 까다로운 상황이 있었지만 그래도 대다수의 경우는 어렵지 않았습니다.
돌이켜보면 CPython의 몇 가지 버그 (TypeDict 관련 bpo-41249), 걷어내야만 했던 일부 라이브러리, 다듬어야 할 수많은 테스트 코드 정도가 기억에 남습니다.
제가 코드베이스에 Lazy Imports를 접목하면서 경험한바 Lazy Imports 적용 시 일반적으로 나타날 수 있는 문제들은 아래와 같습니다.
- 모듈을 불러올 때 발생하는 사이드 이펙트에 의존하는 문제:
- 모듈 import 시점에 임의로 어떤 로직이 실행되는 경우.
- 상위 모듈에서 하위 모듈을 인자로 선언하여 의존하는 경우.
- 파이썬 동적 경로 관련 문제. 예를 들면 모듈 경로를
sys.path에 추가 후 import 후에 다시 제거하는 등의 경우. ModuleNotFoundError를 포함한 모든 에러가 import 시점에서 모듈이 사용되는 시점으로 지연되면서 디버깅이 번거로워지는 문제.- 타입 annotation을 적용하는 경우 세심한 주의가 필요하며, 누락된 경우 Lazy Import가 깨져버리는 문제:
- 모듈마다
from __future__ import annotations구문을 반드시 선언해야 하고, - 스트링 타입 어노테이션으로는
typing.TypeVar()와typing.NewType()을 사용해야 하며, - 타입 alias는
TYPE_CHECKING블럭 내부에서 처리해야합니다.
- 모듈마다
더 포괄적인 문제들은 여기를 참고해주세요.
강점
모듈을 사용 시점에 로드하는 lazy import가 완전히 새로운 개념이 아니고 간단한 방식이었지만, 아무도 CPython 내부에 직접 구현할 생각을 하지 못했으며 이전에 시도한 방식도 지금 Cinder에 도입한 구현체와도 거리가 있습니다. Lazy Imports의 강점은 아래와 같습니다.
- 파이썬을 지연시키는 목적으로 사용되는 패러다임 중 가장 자연스럽고, 강력하며 명료한 방법입니다.
- 적용하는데 크게 어렵지 않습니다. Lazy Imports 기능을 언어 레벨에 전역으로 설정해 두었으며 단일 모듈이나 표준 및 서드파티 라이브러리에도 적용 가능합니다.
- 효율적입니다. 저희 서버에 여러 테스트를 진행했는데, Lazy Imports를 추가하더라도 성능에 큰 영향을 미치지 않았습니다. 오픈소스 pyperformance를 3회 실행하여 측정하였는데, Lazy Imports를 적용하지 않았을 때와 적용했을 때의 성능을 비교하여 아래와 같이 유의미한 결과를 얻었습니다.

- 순환 참조가 발생하지 않습니다. 단순히 Lazy Imports가 직접 순환 참조를 걸러낸다는 의미가 아닙니다. 여전히 모듈 간의 순환 의존성이 존재할 수 있으나 대부분의 순환 의존성은 큰 문제가 없는 일반적인 상황입니다. 인스타그램에서는 매일마다 80개의 순환 참조 에러가 발견되었지만, 현재는 발생하지 않고 있습니다.
향후 전망
- Lazy Imports를 적절히 개선하여 메모리 확보, 서버 재시작 시간 개선뿐 아니라 인스타그램 서버의 성능까지 이끌어낼 수 있습니다.
- 순환 참조에 대한 염려가 사라지면서 코드베이스의 품질을 높이는 새로운 길을 열어줍니다. 리팩토링이 더욱 간편해지고 불가능했던 일이 가능해집니다.
- 외부 서드파티 라이브러리와 협력하여 Lazy Imports와 호환 가능하도록 하여 많은 어플리케이션이 활용할 수 있도록 합니다.
- 보다 광범위한 세계관에서 Lazy Import를 사용할 수 있도록 파이썬 프로젝트에 기여합니다.
원문 보기
Python Lazy Imports With Cinder
Python is widely touted as one of the most developer-friendly languages, thanks to the fast feedback loop that comes from not needing to compile. However, when used at scale in Instagram Server, we’ve found a major usability problem when developing locally; every single change to any Python file requires developers to perform a slow server reload (~50 seconds on average!) to observe the effects of their change.
At Meta, we’ve tackled this problem by creating Lazy Imports: a Python runtime feature that provides a transparent and robust mechanism to lazy loading. Using this technique, we’ve saved hundreds of developer hours per day by reducing the cost of reloads by ~70%, allowing developers to iterate more quickly.
A Cold Cup of Coffee
It all starts one morning. You wake up, pour yourself a hot cup of coffee and head to your laptop to start a productive day. You have a ton of great ideas about the things you are going to accomplish during the day. You rebase and the server is reloading while you take a sip of coffee. The day begins!
As usual, you edit a few files, so the server needs to reload.
It takes some time to restart and we’re all good… until…
there’s this bug that gives you an error, one of those obscure things you know nothing about or where it comes from.
You need to add some logging so you modify one of the files listed in the traceback… ten seconds, twenty, sixty seconds… server still reloading… bang!
Syntax error in your logging line!
You fix the error and then save the file… server starts reloading again… reloading… reloading some more…
After two minutes, you are ready to see your logs.
An hour later, you finally nail the bug, it was that one line you removed two days ago, an import, which unfortunately triggered an obscure import cycle after fetching and rebasing the latest code.
To this point, you’ve just burned a couple hours of your morning and got distracted from what you were supposed to get done today. Worst of all, your coffee is now cold!
You get the picture; waiting times for server reloads pile up throughout your day, and everyone else’s for that matter. That adds up quickly. Soon minutes become hours and hours become days, all wasted time.
Slow Server Reloads
Starting Instagram Server, we spend a large amount of time loading modules. Often, modules are highly entwined, which makes it hard to stop an Import Domino Effect when importing anything.
A server reload took around 25 seconds in late 2021. This time has historically been constantly regressing — an ongoing battle for years. If we don’t pay close attention to keeping it optimized, reload times go up quickly; through 2021 it saw new heights. At its peak, by the end of the year, some reload times were taking as long as 1.5 minutes. This, unfortunately, is the perfect amount of time for engineers to get distracted by something shiny and forget what they are doing.
Why is the server so slow?
Codebase Complexity
The main reason for slow reloads is the increasingly complex codebase that we have in Instagram, together with the fact that we have a ton of modules making lots of references.
If you have never seen an image of how complex the dependency graph of Instagram Server code is, Joshua Lear spent a full day preparing one. After 3 hours of running a modified dependency visualization script, he came back to a “large, black ball.” At first he thought the dependency analyzer had a bug, but it turns out Instagram Server’s dependency graph was a giant circle.
Recreation (artistic interpretation) of Instagram Dependency Graph, by Joshua Lear
In all truth, the dependency graph in the Instagram codebase is a big ugly mesh; everything is very tightly connected. Just starting the server automatically triggers loading a huge number of modules, about 28,000, and most of that startup time is spent, literally, just importing modules, creating Python functions and class objects. A nicer looking dependency graph was first provided by Benjamin Woodruff and updated to reflect the current state:
Real Instagram Dependency Graph, January 2022
So what’s the problem? Just figure out the heavy dependencies and remove them from the code in the hot path, right? Not quite.
Circular Imports
Highly complex code and entwined dependencies are a recipe for disaster. Refactoring to keep dependencies clean and minimal sounds like the obvious fix, but the biggest point of friction is circular imports. As soon as you start trying to refactor, import cycles pop up everywhere.
Import cycles make refactoring harder and have historically produced several outages; even changing the import order can trigger an import cycle somewhere, either immediately or pretty soon for someone else.
A Beam of Light
In the past we’ve tried to refactor modules to break import cycles and simplify the dependency graph. We’ve tried carefully tailoring solutions by making expensive subsystems lazy, e.g., Django Urls, Notifications, Observers, even Regular Expressions. This works to a certain extent, but produces fragile solutions. Through the years, countless hours were spent trying to solve this by manually profiling, refactoring and cleaning things up, only to realize that much goes down the drain pretty soon as code and complexity continues growing. This process is hard, fragile and does not scale well.
What we needed was a robust way of lazyfing all things.
Lazy Imports
Two-toed sloth courtesy of Geoff Gallice via Creative Commons
We needed a more transparent, automatic, reliable and permanent way to make things lazy, instead of manually trying to make things lazy by using inner imports, import_module(), or __import__().
The envisioned project was ambitious and risky, but I rolled my sleeves, dove deep into CPython and started implementing Lazy Imports in Cinder.
Lazy Imports changes the mechanics of how imports work in Python so that modules are imported only when they are used.
At its core, every single import (e.g., import foo) won’t immediately load and execute the module, it will instead create a “deferred object” name.
That name will internally remain an instance of a deferred object until the name is used, which could be in the next line after importing it, or in a deep call stack, many hours later.
After a few weeks working on it, I was able to get a prototype. It was working, it was good and very promising; little did I know of the uphill battle that lay ahead. The hard part was going to be making things rock solid, making the implementation super efficient and rolling it out without too many hiccups. Changing the Python semantics, the way this feature does, would prove to be much more complex than I initially thought, and there were a lot of unexpected wrinkles to discover and fix along the way.
There are many quirks and nuances in the way Python works internally, and the Lazy Imports deferred objects unexpectedly leaked out of the C world into Python. After some very productive discussions with Carl Meyer and Dino Viehland, I decided to redesign the machinery and move most of it deeper, into the heart of Python: the dictionary internals. I was very excited, but modifying the highly optimized implementation of dictionaries could lead to a really bad performance penalty, so I took a lot of care on this part and optimizations took a fair amount of time.
At last, I was able to get a reliable and efficient version working. I enabled Lazy Imports in tens of thousands of Instagram Server modules and started running performance experiments on it to see if it would make any performance difference in production (it shouldn’t). Sure enough, the net looked like almost a wash, we didn’t see any clear signal that the implementation would affect negatively in production and I finally had a perf neutral build too.
Results
In early January 2022, we rolled out to thousands of production and development hosts with no major issues, and we could immediately see the difference in Instagram Server start times in the graphs:
By loading ~12x less modules, we measured a ~70% reduction in p50 reload time and a ~60% reduction in p90 reload time for Instagram development servers. At the same time, it virtually got rid of all import cycle error events we were seeing every day. Other servers and tools consistently saw improvements between 50% to 70% and memory usage reduction of 20% to 40%.
Can you guess when Lazy Imports was enabled in the graph?
See additional results here.
Challenges
Along the way, I ran into many obstacles, too many to list in this post.
Some were more complex than others, but all of them were interesting and challenging.
I can recall a couple bugs in CPython (bpo-41249, related to TypedDict), some libraries that I had to remove and a whole bunch of tests that I had to fix.
In my journey making codebases compatible with Lazy Imports, the problems that are more common when we start using Lazy Imports are:
- Related to modules relying on Import Side Effects:
- Code executing any logic when being imported.
- Relying on submodules being set as attributes in the parent modules.
- Issues related to dynamic Python paths; particularly adding (and then removing after the import) paths from
sys.path. - All the errors are deferred from import time to first-use time (including
ModuleNotFoundError), which might complicate debugging. - Care should be taken when applying type annotations or it could inadvertently defeat Lazy Imports:
- Modules should use
from __future__ import annotations. - We should use string type annotations for
typing.TypeVar()andtyping.NewType(). - Wrap type aliases inside a
TYPE_CHECKINGconditional block.
- Modules should use
For more comprehensive issues and gotchas, see here.
Highlights
Even though the concept of lazy imports is not entirely new and is conceptually simple (i.e., deferring module loading until imported names are used), we are not aware of any other low level implementation directly in CPython internals and none of the previous efforts matches our current implementation in Cinder. Some of its highlights are:
- It provides an automatic, robust and mostly transparent solution to the often used paradigm of making things lazy in Python.
- It needs little effort to be used. We can turn Lazy Imports on globally, as a language level feature, and have Python load every single module and package ever being used lazily (even third party and standard library packages).
- It’s efficient. We ran a series of experiments in our live servers and results were performance neutral when adding the Lazy Imports patch (but not enabling the feature). We also ran the open source pyperformance 3 times, and observed the following most significant results when Lazy Imports is enabled vs. without the patch:
- No more import cycles. That doesn’t mean there can’t be circular imports with Lazy Imports enabled. There can still be legitimate cyclic dependencies at module level, but most cycles won’t be harmful and won’t manifest themselves as import errors. In our use case at Instagram, we went from engineers seeing ~80 circular import errors every day to zero.
- It Just Works™️ (most of the time).
What Lies Ahead
- With the right amount of warmup, Lazy Imports would for sure give us some gains in memory usage, startup times and perhaps (hopefully) even some performance wins in Instagram production servers.
- Not having to worry about Circular Imports, Lazy Imports opens a whole new avenue for modernizing and improving the quality of codebases. Refactoring becomes much easier and things that were once impossible are now feasible.
- Work with external third-party packages and libraries so that they are lazy-imports-friendly, making it possible for many more applications to take advantage of this capability.
- Upstreaming Lazy Imports to make it available to the broader Python ecosystem!
References