
해당 포스트는 Meta Engineering 블로그의 Introducing Immortal Objects for Python 포스트를 번역한 글입니다.
게시일: 2023.08.15
파이썬에 불멸 객체 도입
Meta에서는 인스타그램 프론트엔드 서버로 파이썬(Django)을 사용하고 있습니다. 해당 환경에서 병렬 처리를 위해 프로세스마다 asyncio 기반의 동시성을 처리하는 멀티 프로세스 아키텍처로 운영하고 있습니다. 하지만 인스타그램 정도 규모의 비즈니스 로직과 서버 요청을 감당하기에는 이러한 구조가 메모리에 부담을 주어 병목지점이 생길 수 있습니다.
이러한 현상을 완화시키기 위해 우리는 가능한 많은 객체를 캐싱하는 pre-fork 웹서버와, 공유 메모리를 통해 읽기 전용 모드로 해당 객체에 접근하는 별도 프로세스들로 구성하였습니다. 이런 접근법이 어느 정도 도움은 되었지만, 면밀히 따져보았을 때 시간이 지날수록 공유 메모리 사용량이 줄어들고 반대로 private 메모리 사용량은 증가하는 현상이 발견되었습니다.
그래서 파이썬의 힙(heap) 메모리를 조사해 보았는데, 대다수 파이썬 객체가 실질적으로 불변(immutable) 객체처럼 전체 런타임 실행 내내 살아있었지만, 레퍼런스 카운팅과 가비지 컬렉션 사이클 작업을 거치면서 이러한 객체에 대한 메타데이터 조정 작업이 수행되었고, 결국 서버 프로세스에 COW(Copy on Write)를 유발한다는 사실을 발견했습니다.
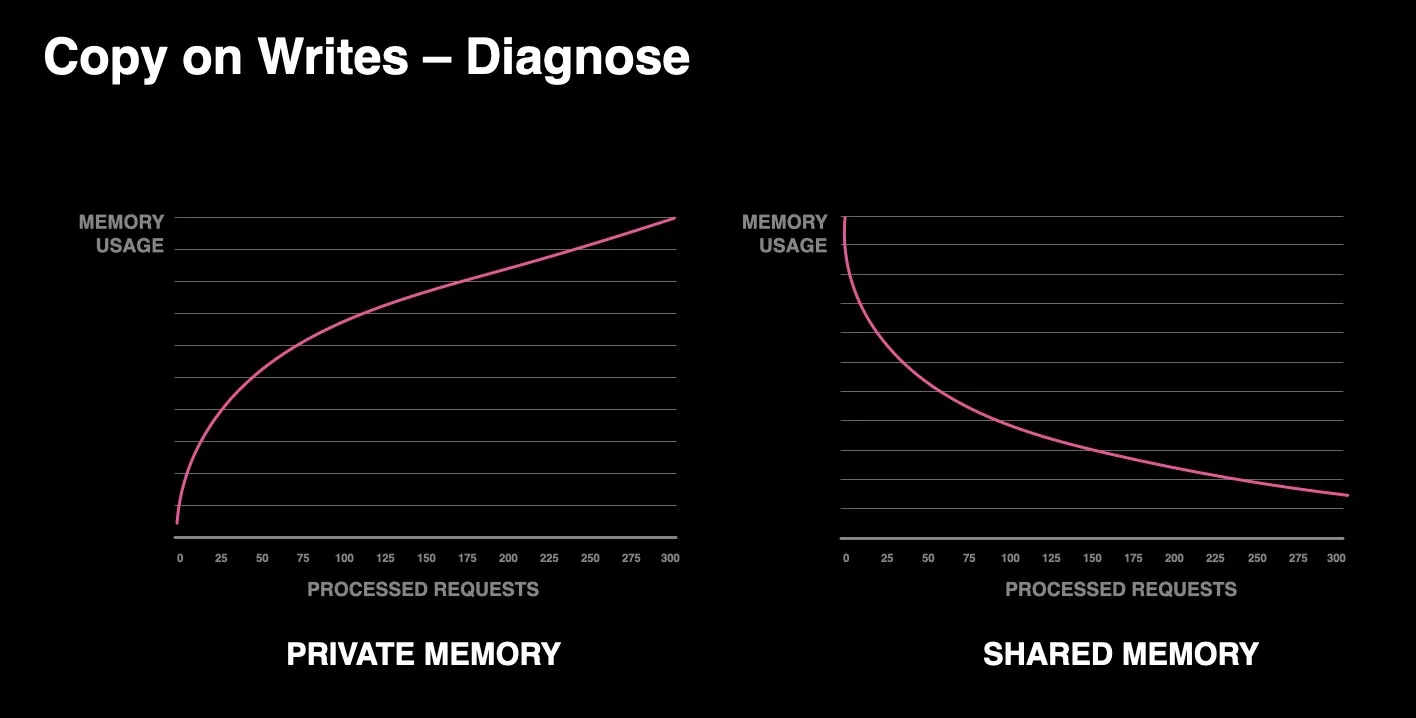 메인 프로세스에서 COW의 영향으로 private 메모리가 늘어나고 공유 메모리가 줄어드는 현상
메인 프로세스에서 COW의 영향으로 private 메모리가 늘어나고 공유 메모리가 줄어드는 현상
파이썬을 위한 불멸 객체
사실 이런 공유 객체 간의 mutation 상태 이슈는 파이썬 런타임이 작동하는 핵심 구성요소입니다. 파이썬 런타임이 레퍼런스 카운팅과 GC 사이클에 의존하고 있기 때문에 객체의 핵심 메모리 구조를 건드릴 수 밖에 없고, 그 때문에 GIL도 불가피한 상황입니다.
우리는 이런 문제를 해결하기 위해 불멸 객체(PEP-683)라는 개념을 도입했습니다. 파이썬 객체의 레퍼런스 카운트 필드에 특별한 값을 표기하면서 핵심 객체의 상태가 절대 변하지 않는 불멸 객체를 고안해 냈습니다. 그래서 런타임이 언제 레퍼런스 카운트 필드와 GC 헤더를 mutate 할 수 있는지 구별할 수 있게 되었습니다.
 표준 객체와 불멸 객체간의 비교. 표준 객체 사용시 타입이나 데이터가 mutate하지 않도록 보장. 불멸성은 추가적으로 런타임이 레퍼런스 카운트나 GC 헤더를 수정하지 않음을 보장하여 전체 객체의 불변성을 활성화.
표준 객체와 불멸 객체간의 비교. 표준 객체 사용시 타입이나 데이터가 mutate하지 않도록 보장. 불멸성은 추가적으로 런타임이 레퍼런스 카운트나 GC 헤더를 수정하지 않음을 보장하여 전체 객체의 불변성을 활성화.
이런 방식을 인스타그램 내부에 적용하는 건 비교적 어렵지 않았지만, 커뮤니티에 발표하기까지 매우 길고 힘든 과정이 있었습니다. 가장 큰 문제는 솔루션의 구현 방식이었습니다. 해당 솔루션은 하위 호환성, 플랫폼 호환성, 성능 저하와 같이 얽혀 있는 복잡한 문제들을 모두 아우르는 해결책을 담아야만 합니다.
먼저, 레퍼런스 카운트 계산 방식이 변경된 후에 특정 객체의 refcount가 갑자기 달라진 상황에서도 프로그램이 크래시가 나지 않아야 합니다.
또한, 파이썬 객체의 핵심 메모리 구현체와 레퍼런스 카운트 증감 메커니즘이 변경되어야 합니다. 그러면서도 그동안 지원하던 모든 플랫폼(Unix, Window, Mac)과 컴파일러(GCC, Clang, MSVC), 아키텍쳐(32-bit, 64-bit), 하드웨어 타입(little-endian, big-endian)에서도 동작해야 합니다.
마지막으로, 해당 구현체의 핵심은 레퍼런스 카운트 증감 부분에 추가한 명시적인 검증 로직인데, 해당 경로는 런타임 실행 중에 가장 빈번하게 호출되는 부분이었습니다. 이에 따라 서비스의 성능 저하가 불가피해졌지만, 다행히도 레지스터 할당 부분을 잘 활용하면서 전반적인 시스템 성능이 고작 2% 하락에 그치도록 하였고, 그 대가로 얻는 성능적인 이익을 생각해 보면 합당한 수치였습니다.
불멸 객체가 인스타그램에 미친 영향
다시 처음으로 돌아와서, 인스타그램의 초기 목표는 COW를 감소시켜서 매 요청마다 메모리와 CPU 효율성을 향상시키는 것이었습니다. 그리고 불멸 객체를 도입하면서 공유 메모리 사용량을 높이고 private 메모리 사용량을 줄일 수 있었습니다.
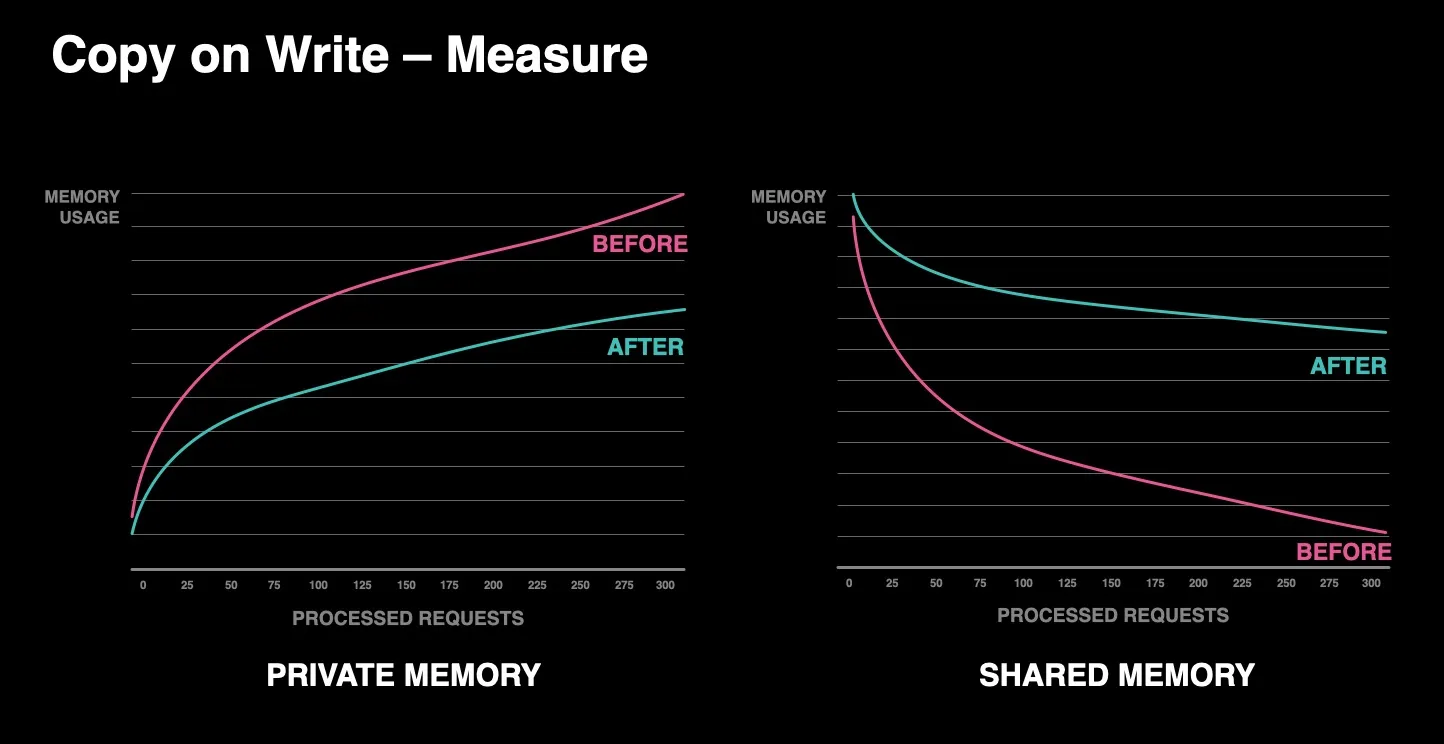 불멸 객체를 사용하면서 공유 메모리 사용량 증가 및 private 메모리 사용량의 현저한 감소. COW 횟수 감소
불멸 객체를 사용하면서 공유 메모리 사용량 증가 및 private 메모리 사용량의 현저한 감소. COW 횟수 감소
이러한 변화는 인스타그램 내부의 개선을 넘어서 파이썬 언어의 진화에도 영향을 주었습니다. 현재까지 파이썬의 제약사항 중 하나는 힙 공간에서 객체의 진정한 불변성을 보장할 수 없다는 것이었습니다. GC와 레퍼런스 카운트 메커니즘 하에서 객체의 레퍼런스 카운트 필드와 GC 헤더에 무제한 접근할 수 있었습니다.
하지만 파이썬에 불멸 객체를 도입하면서 최초로 진정한 불변성을 보장하였습니다. 이에 따라 특정 객체는 레퍼런스 카운팅과 가비지 컬렉션 대상에서 제외될 수 있습니다. 즉, 굳이 GIL 없이도 불멸 객체를 스레드 간에 공유할 수 있게 되었습니다.
이런 방식은 multi-core 파이썬을 향한 중요한 기반이 될 수 있습니다. 이를 위해 불멸 객체를 활용하는 방법으로 아래 두 가지 제안이 있습니다.
오늘날 불멸 객체
우리는 커뮤니티와 함께 이러한 ‘불멸화’의 개념을 서로의 시스템에서 잘 활용하는 방법을 고민해 보고, 기존 제안을 살펴보면서 multi-core 환경에서 어플리케이션을 개선할 방안을 기대하고 있습니다. Meta에서는 이러한 언어의 발전 방향에 흥미를 느끼고 있으며, 인스타그램을 연구하고 발전시키면서도 회사 외적으로 기여할 준비가 되어있습니다.
원문 보기
Introducing Immortal Objects for Python
At Meta, we use Python (Django) for our frontend server within Instagram. To handle parallelism, we rely on a multi-process architecture along with asyncio for per-process concurrency. However, our scale – both in terms of business logic and the volume of handled requests – can cause an increase in memory pressure, leading to efficiency bottlenecks.
To mitigate this effect, we rely on a pre-fork web server architecture to cache as many objects as possible and have each separate process use them as read-only structured through shared memory. While this greatly helps, upon closer inspection we saw that our processes’ private memory usage grew over time while our shared memory decreased.
By analyzing the Python heap, we found that while most of our Python Objects were practically immutable and lived throughout the entire execution of the runtime, it ended up still modifying these objects through reference counts and garbage collection (GC) operations that mutate the objects’ metadata on every read and GC cycle – thus, triggering a copy on write on the server process.
The effect of copy on writes is increasing private memory and a reduction of shared memory from the main process.
Immortal Objects for Python
This problem of state mutation of shared objects is at the heart of how the Python runtime works. Given that it relies on reference counting and cycle detection, the runtime requires modifying the core memory structure of the object, which is one of the reasons the language requires a global interpreter lock (GIL).
To get around this issue, we introduced Immortal Objects – PEP-683. This creates an immortal object (an object for which the core object state will never change) by marking a special value in the object’s reference count field. It allows the runtime to know when it can and can’t mutate both the reference count fields and GC header.
A comparison of standard objects versus immortal objects. With standard objects, a user can guarantee that it will not mutate its type and/or its data. Immortality adds an extra guarantee that the runtime will not modify the reference count or the GC Header if present, enabling full object immutability.
While implementing and releasing this within Instagram was a relatively straightforward process due to our relatively isolated environment, sharing this to the community was a long and arduous process. Most of this was due to the solution’s implementation, which had to deal with a combination of problems such as backwards compatibility, platform compatibility, and performance degradation.
First, the implementation had to guarantee that, even after changing the reference count implementation, applications wouldn’t crash if some objects suddenly had different refcount values.
Second, it changes the core memory representation of a Python object and how it increases its reference counts. It needed to work across all the different platforms (Unix, Windows, Mac), compilers (GCC, Clang, and MSVC), architectures (32-bit and 64-bit), and hardware types (little- and big-endian).
Finally, the core implementation relies on adding explicit checks in the reference count increment and decrement routines, which are two of the hottest code paths in the entire execution of the runtime. This inevitably meant a performance degradation in the service. Fortunately, with the smart usage of register allocations, we managed to get this down to just a ~2 percent regression across every system, making it a reasonable regression for the benefits that it brings.
How Immortal Objects have impacted Instagram
For Instagram, our initial focus was to achieve improvements in both memory and CPU efficiency of handling our requests by reducing copy on writes. Through immortal objects, we managed to greatly reduce private memory by increasing shared memory usage.
Increasing shared memory usage through immortal Objects allows us to significantly reduce private memory. Reducing the number of copy on writes.
However, the implications of these changes go far beyond Instagram and into the evolution of Python as a language. Until now, one of Python’s limitations has been that it couldn’t guarantee true immutability of objects on the heap. Both the GC and the reference count mechanism had unrestricted access to both of these fields.
Contributing immortal objects into Python introduces true immutability guarantees for the first time ever. It helps objects bypass both reference counts and garbage collection checks. This means that we can now share immortal objects across threads without requiring the GIL to provide thread safety.
This is an important building block towards a multi-core Python runtime. There are two proposals that leverage immortal objects to achieve this in different ways:
Try Immortal Objects today
We invite the community to think of ways they can leverage immortalization in their applications as well as review the existing proposals to anticipate how to improve their applications for a multi-core environment. At Meta, we are excited about the direction in the language’s development and we are ready to keep contributing externally while we keep experimenting and evolving Instagram.
References