
1. 테이블 부풀림 현상
PostgreSQL 에서 UPDATE 동작 과정과 관련된 간단한 실험을 하기 위해 임의의 테이블을 생성한 후 10만개의 값을 넣고 모든 row 에 대하여 업데이트 작업을 하였습니다.
CREATE TABLE test_table (a int, b int);
ALTER TABLE test_table SET (autovacuum_enabled = false);
INSERT INTO test_table
SELECT generate_series, generate_series
FROM generate_series(1, 100000);
SELECT pg_size_pretty(pg_total_relation_size('test_table')); -- 테이블 사이즈 체크
-- 3568 kB
UPDATE test_table
SET a = a + 1;
SELECT pg_size_pretty(pg_total_relation_size('test_table'));
-- 7104 kB
UPDATE test_table
SET b = b + 1;
SELECT pg_size_pretty(pg_total_relation_size('test_table'));
-- 10 MB
별도 데이터를 입력하지 않고 단순히 업데이트 작업만 하였지만 테이블의 크기가 늘어난 것을 확인할 수 있습니다. 동일한 현상이 DELETE 시에도 발생합니다.
DELETE FROM test_table;
SELECT count(*) FROM test_table
-- 0
SELECT pg_size_pretty(pg_total_relation_size('test_table'));
-- 10 MB
모든 row가 지워진 것처럼 보여지지만 테이블의 크기는 여전히 줄어들지 않습니다. 다소 비정상적인 상황처럼 보이지만 사실 PostgreSQL 은 이런 방식으로 작동하도록 설계되었습니다.
PostgreSQL에서 UPDATE 는 마치 DELETE & INSERT 와 같은 방식으로 작동합니다. 하나의 row를 업데이트 하는 과정에서 기존 공간은 비활성화하고 새로운 디스크 공간을 할당하여 그곳에 데이터를 새로 저장하게 됩니다. DELETE 작업도 마찬가지로 데이터를 실제로 삭제하지 않고 기존 테이블 공간에 그대로 남겨둡니다.
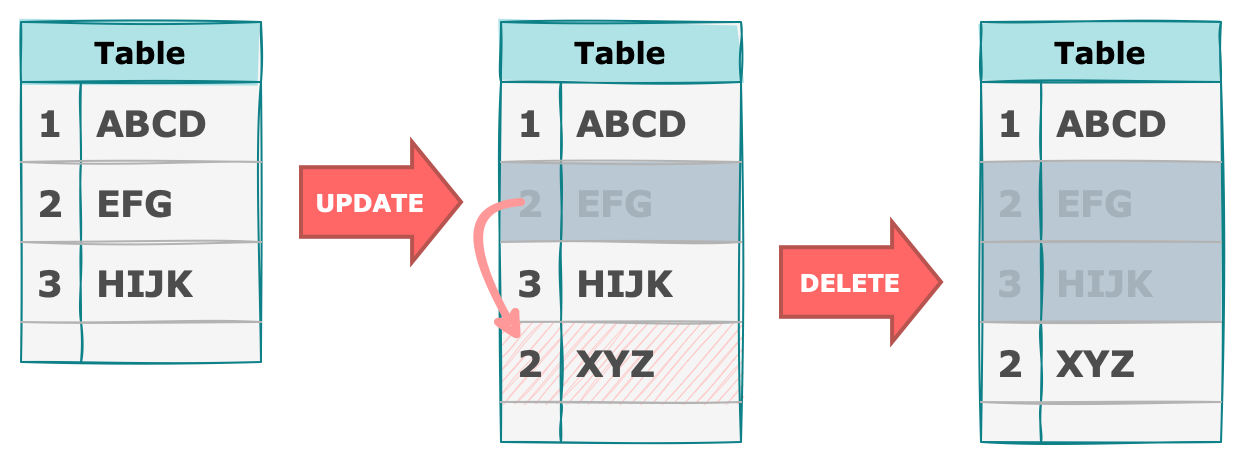
이러한 과정이 반복되면 중간 중간에 사용하지 않는 공간인 dead tuple 이 많이 생기는데, 늘어난만큼 디스크의 용량을 잡아먹으며 데이터를 읽는 시간도 증가하게 됩니다. 이렇게 중간중간 비어있는 튜플을 지우지 않고 남겨두는 이유는 다중 버전 동시성 제어를 위해서 입니다.
2. 다중 버전 동시성 제어 (MVCC)
다중 버전 동시성 제어(Multi-Version Concurrency Control) 이란 하나의 데이터 객체에 대해서 여러 개의 버전을 통해 관리하는 기법을 말합니다. RDB는 기본적으로 데이터 READ & WRITE 작업을 신속히 하도록 설계되어있는데, READ 와 WRITE 요청이 동일한 객체에 빈번히 들어온다면 그때마다 lock을 걸어주는건 성능이 너무 떨어지게 됩니다.
PostgreSQL에서는 버전 관리를 위해 튜플마다 xmin, xmax 값을 추가적으로 가지고 있습니다. 기본적으로 새로 만들어진 튜플은 xmin 에 해당 객체를 생성했던 트랜잭션의 ID가 입력되고 xmax 값은 Null 입니다. 추가적으로 새로운 버전이 만들어지면 이전 버전에서 새 버전으로 연결되는 link 가 생성됩니다.
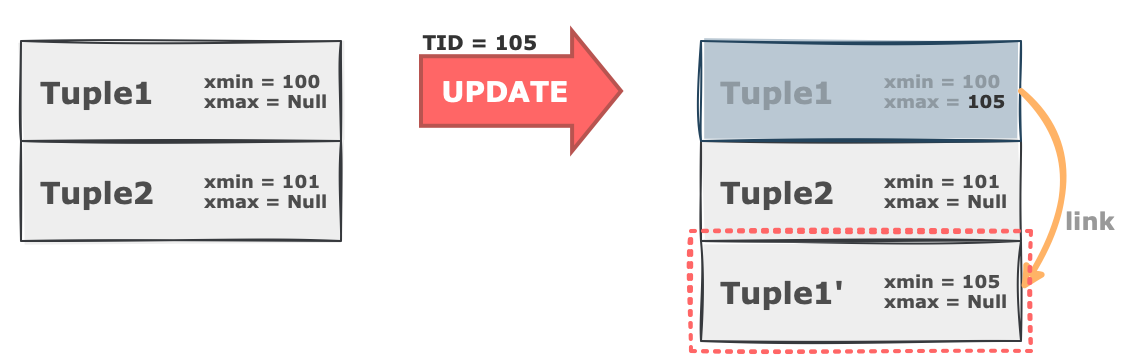
이때 특정 튜플에 대하여 UPDATE 요청이 들어오게 되면 새 버전을 같은 테이블 공간 맨 뒤에 append 시킵니다. 이전 버전의 xmax 와 새 버전의 xmin에는 해당 작업을 수행한 트랜잭션의 ID가 입력됩니다. 이전 버전은 없어지지 않고 계속 남아있게 됩니다.
반면 SELECT 요청이 들어오면 먼저 테이블의 heap 공간으로 가서 해당 튜플의 최소 버전을 찾습니다. 해당 튜플을 읽어서 xmax 값이 존재하는 경우 연결된 링크를 따라 다음 버전으로 이동하면서 읽을 수 있는 가장 최신 버전을 찾을 때 까지 모든 버전을 거쳐가야 합니다.
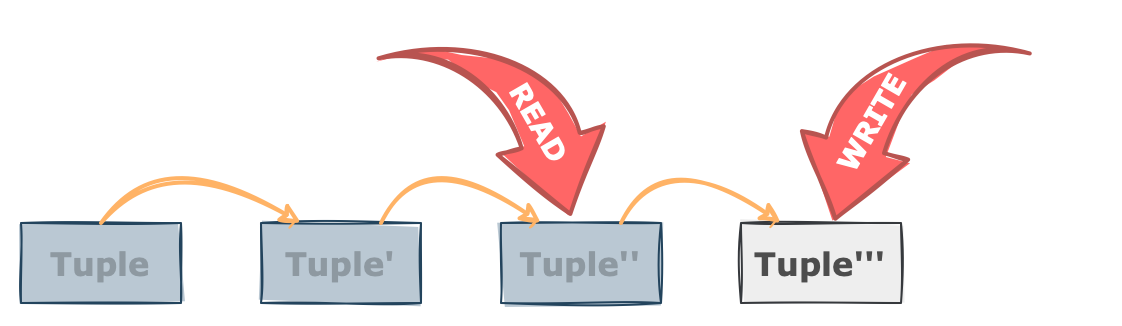
이런 식으로 동작하면 READ 와 WRITE 요청이 동시에 들어와도 서로 바라보는 버전이 다르기 때문데 lock 없이 동시성을 보장 할 수 있습니다.
3. Vacuum
이런 기법을 이용하면 동시성 문제는 해결되지만 dead tuple 들이 계속 공간을 차지하고 있는 문제가 남아있습니다. 또한 데이터를 SELECT 할 때 초기 버전부터 가장 최신까지 모두 읽어야 하므로 해당 데이터의 UPDATE 이력이 쌓여가면서 READ 성능이 점점 떨어질 수 있습니다.
이러한 문제를 해결하기 위해 vacuum 이라는 프로세스를 도입했습니다. 매 테이블마다 사용하지 않는 dead tuple 들을 다시 free space 로 바꾸어 다시 데이터를 저장할 수 있는 상태로 되돌립니다.
Vacuum 작업시 진행되는 작업은 다음과 같습니다.
- dead tuple 들을 free space 로 변경
- 테이블의 Visibility map, Free Space Map 파일의 내용 갱신
- 각 테이블의 통계 정보 갱신 (
pg_class,pg_stat_tmp,pg_statistics) - 트랜잭션 겹침 방지 작업
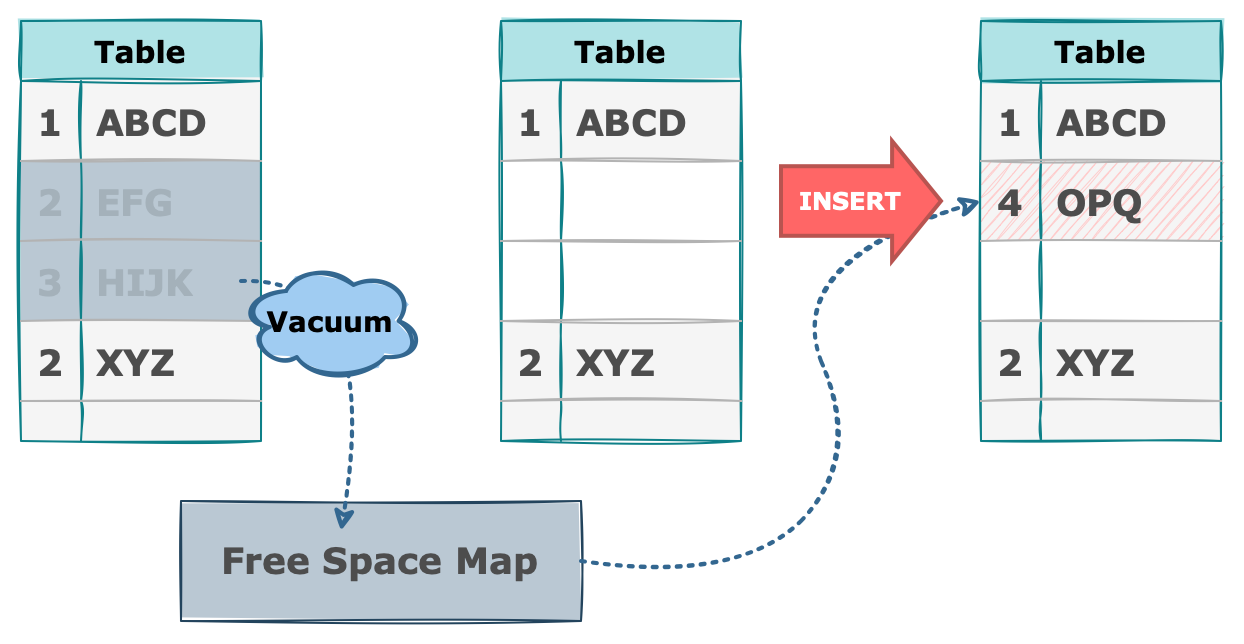
한 번 늘어난 테이블의 크기는 vacuum 작업을 거쳐도 다시 줄어들지 않습니다. 다만 다음 INSERT 요청시 free space로 변경되었던 공간에 데이터가 입력되므로 남아있는 free space 가 다 차기 전 까지는 테이블의 크기가 증가하지 않습니다.
References