
QuerySet은 Django 모델 객체로부터 생성되는 객체입니다.
내부에 DB 조회에 대한 정보를 담고 있으며 Django ORM을 위한 기본적인 API 인터페이스를 제공합니다.
1. lazy loading
기본적으로 QuerySet은 객체 생성 시 바로 쿼리를 실행하지 않고 평가해야 할 시점이 되면 쿼리를 실행시킵니다. 공식 문서에서 설명하고 있는 구체적인 시점은 다음과 같습니다.
- Iteration 작동 시
- for 문과 같이 QuerySet 객체를 순차적으로 iterate 하는 시점이 오면 쿼리를 실행시킵니다. 한 번 쿼리를 통해 가져온 데이터는 QuerySet 내부에 캐싱 됩니다.
- Slicing 사용 시
- QuerySet도 일반적인 파이썬 array 구조체처럼 슬라이싱이 가능합니다.
- 일반적으로 QuerySet을 슬라이싱 하면 내부에
LIMIT,OFFSET로직으로 전환되고 다른 QuerySet을 반환하지만 슬라이싱에[::2]와 같은 step 파라미터가 포함된 경우 즉시 쿼리를 실행시켜 데이터를 가져옵니다.
- Pickling / Caching 작업 시
- repr(), len(), list(), bool() 메소드 호출 시
- 다만, 데이터 record의 개수가 필요한 경우엔
__len__보다는 count() 메소드를 사용하는 게 더 효율적입니다.
- 다만, 데이터 record의 개수가 필요한 경우엔
즉, 객체 생성 시 바로 쿼리가 실행되는 것이 아니라 객체 내부에 차곡차곡 로직을 담고 있다가 조건이 만족되면 쿼리를 날려 데이터를 가져옵니다.
users = User.objects.filter(is_active=True)
users = users.filter(created_at__lt=datetime(2022, 1, 1))
users = users.exclude(user_status="withdraw")
for user in users: # 이때 쿼리 실행!
print(user)
2. 모델 Join
Django ORM 에서는 모델을 조인하는 기능을 제공하고 있습니다. 다음과 같은 모델을 예로 들어 살펴봅시다.
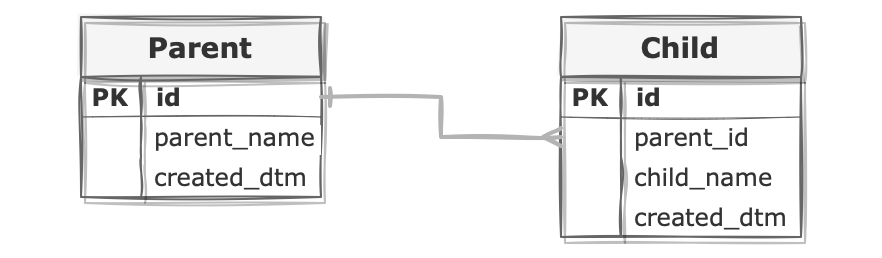
class Parent(models.Model):
parent_name = models.CharField(max_length=32)
created_dtm = models.DateTimeField(auto_now_add=True)
class Child(models.Model):
parent = models.ForeignKey(Parent, on_delete=models.CASCADE)
child_name = models.CharField(max_length=32)
created_dtm = models.DateTimeField(auto_now_add=True)
아래와 같은 코드를 작성한다면 매 루프마다 쿼리를 실행하게 되는데 Django 프로젝트 내에 이런 방식의 로직이 많다면 DB에 많은 부하를 주게 됩니다.
childs = Child.objects.all()
for child in childs:
print(child.parent.parent_name)
-- child 테이블 read
SELECT id, parent_id, child_name, created_dtm FROM child
-- parent 테이블 read
SELECT id, parent_name, created_dtm FROM parent WHERE id = 1
SELECT id, parent_name, created_dtm FROM parent WHERE id = 2
SELECT id, parent_name, created_dtm FROM parent WHERE id = 3
...
2.1 select_related
select_related를 활용하면 필요한 모델을 사전에 조인하여 가져와서 DB 부하를 줄일 수 있습니다.
해당 메소드는 다른 모델과 정참조(OneToOne, ManyToOne, ForeignKey)로 연결된 경우만 실행할 수 있습니다.
다음 코드는 바로 위에서 실행했던 코드와 같은 결과를 반환하지만, DB transaction은 단 한 번만 실행되었습니다.
childs = Child.objects.select_related("parent").all()
for child in childs:
print(child.parent.parent_name)
-- child, parent 모델 join
SELECT child.id
, child.parent_id
, child.child_name
, child.created_dtm
, parent.id
, parent.parent_name
, parent.created_dtm
FROM child
INNER JOIN parent ON child.parent_id = parent.id
2.2 prefetch_related
해당 메소드도 마찬가지로 연결된 모델을 가져오는데 다른 모델과 역참조(ManyToMany, OneToMany, 역참조 ForeignKey)로 연결된 경우 사용합니다.
다만 select_related처럼 쿼리상에서 조인하지 않고 개별로 데이터를 가져와 파이썬 내부에서 연결시킵니다.
parents = Parent.objects.prefetch_related("child_set").all()
for parent in parents:
print(parent.child_set.all())
-- parent 테이블 read
SELECT id, parent_name, created_dtm FROM parent
-- child 테이블 read
SELECT id, parent_id, child_name, created_dtm FROM child WHERE parent_id IN (1, 2, 3)
2.3 Raw Query
Django ORM 에서 제공하는 기능이 영 맘에 안 들거나 혹은 ORM이 생성하는 쿼리가 성능에 문제가 있다고 판단되면 직접 SQL 쿼리를 작성하는 방법으로 해결할 수 있습니다.
queryset = User.objects.raw(
""" SELECT p.id
, p.parent_name
, count(*) AS cnt
FROM parent AS p
, child AS c
WHERE p.id = c.parent_id
GROUP BY p.id, p.parent_name
ORDER BY cnt DESC """
)
type(queryset)
# <class 'django.db.models.query.RawQuerySet'>
대신 실행한 결과로 QuerySet이 아닌 RawQuerySet 을 반환합니다.
2.4 ORM vs Raw query
한 번의 이직을 겪으면서 raw query를 적극 사용하는 회사도 겪어보았고 ORM을 활용하는 회사도 경험해 보았습니다. 각 회사가 서로 비슷한 도메인도 아니었고 프로젝트의 성격도 다르기에 어떤 방식이 더 우월하다는 정답은 없지만 제가 느낀 바를 정리하였습니다.
우선 raw query를 사용한 경우 많은 과정이 직관적이고 단순해집니다.
복잡한 데이터를 가져오는 경우 파이썬으로 코드를 작성하고 ORM이 생성한 쿼리를 다시 교차 검증하는 불필요한 과정 없이 SQL만 작성하면 됩니다.
또한 만일 SQL에 능숙하다면 hint를 사용하여 특정 인덱스를 태우거나 테이블 조인 순서도 조정할 수 있고(물론 대부분 경우는 옵티마이저가 알아서 잘해주겠지만..),
PostgreSQL를 사용한다면 array_to_json과 같은 function으로 아예 serialize과정까지 SQL로 가능합니다.
상대적으로 파이썬 코드를 작성하는 부분은 줄어들어서 성능적인 부분에 좀 더 집중할 수 있습니다.
다만 단점이 있다면 한 번 작성한 쿼리는 확장성이 매우 떨어진다는 것입니다. 파이썬 코드상에서 SQL 쿼리라는 녀석은 하나의 string 덩어리로 다뤄지기 때문에 정적인 로직만을 실행하는 데 특화되어 있습니다. 따라서 비슷한 기능을 개발할 때에도 기존 작성한 쿼리를 활용하지 못하고 다시 새로운 쿼리를 작성해야만 합니다. 이를 개선하기 위해 반복되는 로직을 재사용하도록 쿼리 중간중간 구멍을 내고 필요한 조건문을 끼워넣어 동적으로 SQL을 생성하는 방법도 있습니다. 하지만 이런 방식을 과도하게 남발하다 보면 쿼리가 잘게 쪼개져 파편화되어 원형을 알아보기 힘들어질 수 있고, SQL 내부에 들어갈 텍스트를 엄밀하게 검증하지 않는 경우엔 보안 측면에서 문제가 될 수 있어서 그렇게 권장하는 방법은 아닙니다. 어떤 방식으로든 쿼리의 유지보수라는 게 꽤 까다로운 작업임에는 분명합니다.
반대로 raw query의 단점은 ORM의 장점이 됩니다. ORM을 사용하게 되면 확장성이 높아지게 되는데, 단적으로 Django 에서는 mixin과 같은 방식으로 QuerySet을 관리하도록 권장하고 있습니다. 반복되는 로직은 mixin 클래스 내부에서 정의해두고 해당 클래스를 상속받아 필요한 부분만 덧붙인다면 관리 포인트를 훨씬 줄일 수 있습니다. 또한 미관상으로도 좋습니다. 파이썬 코드 중간중간 빼꼼 고개를 내미는 SQL은 상당히 어색하고 가독성에 많은 방해가 됩니다.
단점으로는 SQL과는 별도로 ORM을 학습해야만 한다는 것입니다. Inner Join, Left Join 등 테이블을 원하는 대로 조인하기가 꽤 까다롭고, ORM에 대한 이해 없이 코드를 작성하면 의도치 않게 비효율적으로 동작하는 경우도 발생합니다. 가끔 복잡한 SQL을 구현하기 위해 document를 뒤적일 때면 꼭 이렇게까지 해야 하나 자괴감이 들 때도 있습니다. ORM을 자신의 입맛에 맞게 사용하려면 반드시 어느 정도의 시간을 들여 내부적으로 동작하는 과정에 대한 이해가 필요합니다.
객체지향 프로그래밍이 대두되면서 추상화, 캡슐화를 통해 개발자의 생산성을 높이는 요즘 트렌트에는 아무래도 ORM을 사용하는 게 적합해 보입니다. 개인적으로도 ORM을 선호하며 도저히 ORM으로는 불가능하다고 생각되는 경우에만 raw query를 사용하는 것이 적합하다고 생각합니다. 그나마도 ORM에서 지원하는 경우가 많아서 대부분의 경우 충분히 ORM으로 커버 가능하다고 생각합니다.
Referneces