
GIL(global interpreter lock)이란 파이썬 바이트코드가 하나의 스레드만 사용하여 실행하도록 CPython 인터프리터 자체에서 스레드를 제한하는 것을 의미합니다. 그렇게 동작하는 이유는 파이썬은 기본적으로 메모리를 관리하는 방식이 thread safe 하지 않기 때문입니다. 동시에 여러 스레드가 실행되면 race condition이 발생해서 프로그램이 제대로 동작하지 않을 수 있으므로 실행되고 있는 한 개의 스레드 외에 다른 스레드는 객체에 접근하지 못하도록 제한하고 있습니다. 이 내용에 대해서는 아래에서 좀 더 자세히 다뤄봅시다.
1. Thread Safe 이슈
이전에 CPython은 기본적으로 레퍼런스 카운팅을 사용하여 메모리를 관리한다고 설명했습니다.
각 스레드에서 객체가 참조될 때마다 ob_refcnt 를 계산해 주어야 하는데, 동시에 여러 스레드에서 동일한 객체에 접근할 때 일부 실행이 누락되는 경우가 발생할 수 있습니다.
이렇게 둘 이상의 스레드가 서로 공유하는 자원에 접근하여 정상적인 동작을 방해하는 경우를 race condition(경쟁 상태)이라고 합니다.
반대로 이런 race condition이 발생하지 않으면서 프로그램이 정상적으로 실행되면 thread safe 하다고 합니다.
파이썬에서 이러한 race condition 상황을 실제로 재현해 볼 수 있습니다.
import threading
x = 0
def increase():
global x
for _ in range(1000000):
x += 1
def decrease():
global x
for _ in range(1000000):
x -= 1
t1 = threading.Thread(target=increase)
t2 = threading.Thread(target=decrease)
t1.start()
t2.start()
t1.join()
t2.join()
print(x)
위 코드에서 글로벌 변수 x가 0으로 정의되어있고 하나의 스레드에서 1씩 증가하며 나머지 하나의 스레드에서 1씩 감소하는 작업을 할당하였습니다.
상식적으로는 마지막에 x가 0으로 출력될 것으로 예상하지만 실제로는 다른 값이 출력되는 것을 확인할 수 있습니다.
즉, 여러 스레드를 실행하면서 몇 개의 작업이 씹혔다는 건데, 이런 식으로 파이썬에서 다중 스레드를 잘못 사용하면 의도치 않은 결과가 나올 수도 있습니다.
위에서 보여지는 현상은 python3.10 버전부터는 나타나지 않는데, 현재는 개선된 것으로 보여집니다.
이런 문제를 해결하기 위해서는 크게 두 가지 방법이 있습니다.
- 스레드가 접근할 때마다 객체에 lock을 걸어서 (mutex) 다른 스레드가 접근하지 못하도록 한다.
- 애초부터 인터프리터에 lock을 걸어서 하나의 스레드만 객체에 접근하도록 한다.
첫 번째 경우를 생각해보면 스레드가 접근할 때마다 해당 스레드가 참조하는 모든 객체에 lock을 걸어야 하는데 성능도 매우 떨어지고, deadlock의 위험도 있습니다. 따라서 파이썬은 두 번째 방법으로 하나의 스레드만 사용하는 방식을 채택하였습니다.
2. Multi Threading
하지만 CPython 기반으로도 멀티 스레드를 잘 활용한다면 좀 더 효율적인 프로그램을 작성할 수 있습니다. 다음 코드를 한 번 살펴봅시다.
import threading
import time
N = 100000000
def count(n):
for _ in range(n):
pass
def single_thread():
start = time.time()
count(N)
count(N)
count(N)
print(time.time() - start)
def multi_thread():
start = time.time()
t1 = threading.Thread(target=count, args=(N,))
t2 = threading.Thread(target=count, args=(N,))
t3 = threading.Thread(target=count, args=(N,))
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print(time.time() - start)
single_thread()
# 5.680222988128662
multi_thread()
# 5.705009937286377
단순 iteration 작업을 single_thread() 함수는 하나의 스레드를 이용하였고 multi_thread() 함수에서는 3개의 스레드에 나누어 실행하였습니다.
하지만 결과를 살펴보면 멀티 스레드를 사용하는 경우가 미세하게 시간이 더 많이 걸리는 것을 확인할 수 있습니다.
앞에서 설명한 바와 같이 CPython은 하나의 스레드만 동작하게 되어있습니다. 그래서 코드만 봐서는 동시에 여러 작업을 하는 것처럼 보이지만 실제로는 각 스레드들이 번갈아가며 자원들 할당받은 후에 작동하기 때문에 매 시점마다 실행되는 스레드는 항상 하나입니다. 또한 이 과정에서 자원을 다시 반납하고 스레드를 옮겨 다시 자원을 할당하는 context switching이 발생하여 시간을 더 잡아먹게 됩니다.
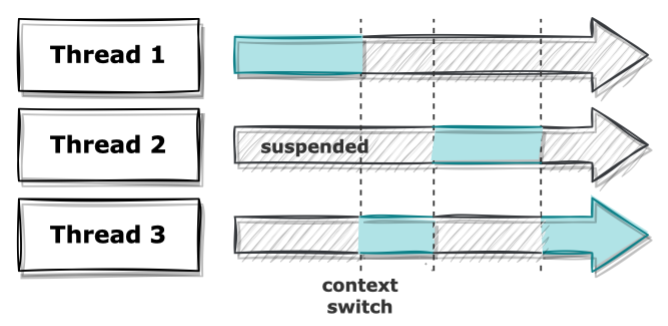
다만 블로킹 입출력을 사용하는 파이썬 내장 라이브러리(I/O, 이미지 처리 등)들은 동시에 여러 스레드가 실행되도록 허용하기도 합니다. 입출력 작업을 하는 동안에는 OS로부터 결과를 가져올 때까지 GIL을 해제하여 다른 스레드가 실행될 수 있도록 하기 때문에 오히려 멀티 스레드로 이득을 볼 수도 있습니다. 위에서 작성한 코드에서 실행하는 함수를 iteration 대신 sleep으로 바꾸면 전혀 다른 결과가 나타납니다.
import threading
import time
SEC = 1
def sleep(n):
time.sleep(n)
def single_thread():
start = time.time()
sleep(SEC)
sleep(SEC)
sleep(SEC)
print(time.time() - start)
def multi_thread():
start = time.time()
t1 = threading.Thread(target=sleep, args=(SEC,))
t2 = threading.Thread(target=sleep, args=(SEC,))
t3 = threading.Thread(target=sleep, args=(SEC,))
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print(time.time() - start)
single_thread()
# 3.0077760219573975
multi_thread()
# 1.00410795211792
동일하게 single_thread()는 하나의 스레드만을 이용하였고, multi_thread()에서는 3개의 스레드를 이용하였습니다.
이번 경우에는 멀티 스레드를 사용한 경우 확실히 시간이 적게 들었는데, time.sleep 함수는 블로킹 입출력 함수라서 실행되는 동안 GIL을 해제하기 때문입니다.
3. Conclusion
파이썬은 메모리를 thread safe 하게 관리하기 위해 GIL을 사용하는 방법을 채택하였습니다. 따라서 여러 I/O 작업을 동시에 실행하는 경우는 여러 개의 스레드로 나누어 실행하는 방식이 유용할 수 있지만, CPU를 사용한 연산 작업이 많다면 큰 효과가 없을 수도 있습니다. 그럼에도 병렬 처리가 필요하다면 좀 더 안전한 멀티 프로세싱이나 큐(queue)를 활용할 수도 있으니 적재적소에 알맞은 방법을 사용해야 합니다.
References
- Luciano Ramalho, Fluent Python: Clear, Concise, and Effective Programming, 강권학, 한빛미디어, 2016-08-12
- Glossary - Python 3.10.2 documentation
- GlobalInterpreterLock - Python Wiki
- 왜 Python에는 GIL이 있는가
- Python의 Global Interpreter Lock[GIL]