
쿠팡, 무신사와 같은 커머스 사이트에 접속해 보면 사용자가 둘러본 히스토리를 보여주는 ‘최근 본 상품’과 같은 섹션이 존재합니다. 사용자가 상품을 클릭할 때마다 상품 정보를 기억하고 있다가 해당 섹션에 상품 리스트를 최신순으로 정렬하여 보여주는 방식입니다.
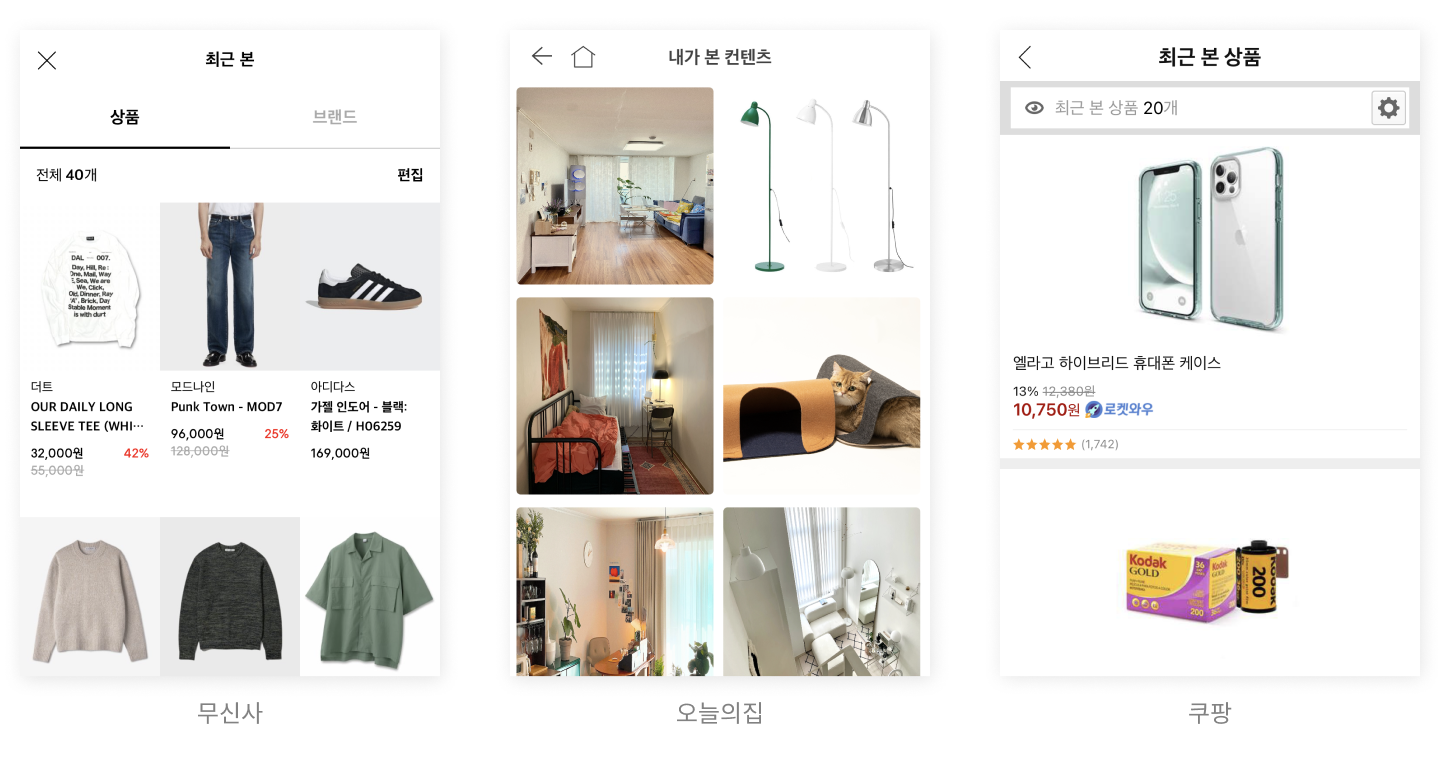
이러한 기능을 구현하기 위해 사용자가 상품을 조회한 내역을 캐싱해야 하는데, 해당 역할을 클라이언트 혹은 서버에서 수행할 수 있습니다. 본 포스트에서는 그중 서버에서 관리하는 방법에 대해 정리해 보았습니다. 특히 해당 기능을 구현하기 위해 Redis의 Sorted Set 자료구조를 접목하였는데, 어떤 방식으로 활용할 수 있는지 아래에서 자세하게 알아봅시다.
1. Sorted Set
Redis 에서는 Sorted Set 이라는 자료 구조를 지원합니다. 간단히 ZSet 이라고도 부릅니다. 보통 자료구조에서 Set 이라고 하면 수학의 집합(set) 개념과 유사하게 순서 없이 중복 없는 원소를 가지는 묶음을 의미하는데, Sorted Set에서는 거기서 더 나아가 멤버(원소) 하나하나마다 순서를 정의한 자료구조입니다.
Sorted Set은 스킵 리스트(Skip List)와 해시 테이블(Hash Table)를 복합적으로 활용하여 구성된 자료구조입니다. 일반적으로 멤버 개수가 128개 이하이면서 멤버의 크기가 모두 64바이트 이하면 Zip List라고 하는 연결 리스트에만 데이터를 저장됩니다. 하지만 해당 조건을 넘어가는 순간 레디스가 자동으로 데이터 구조를 변환하여 스킵 리스트와 해시 테이블에 저장됩니다. 아래에서 Sorted Set의 동작과 관련해서는 Zip List 대신 스킵 리스트 기반으로 설명하겠습니다.
1.1 ZADD
ZADD 명령어를 이용하여 Sorted Set에 값을 추가할 수 있습니다.
이때 멤버 간의 순서를 정해주어야 하므로 멤버 외에 순서를 정해줄 ‘스코어(score)’까지 입력해야 합니다.
CLI 명령어로는 아래와 같이 ZADD key score member 순으로 입력합니다.
> ZADD key1 1234 value1 # value1 원소를 score 1234로 저장
(integer) 1
> type key1 # 타입을 확인해보면 zset으로 조회
zset
원소 하나를 추가할 때마다 레디스 내부 스킵 리스트와 해시 테이블에서는 다음 과정이 진행됩니다.
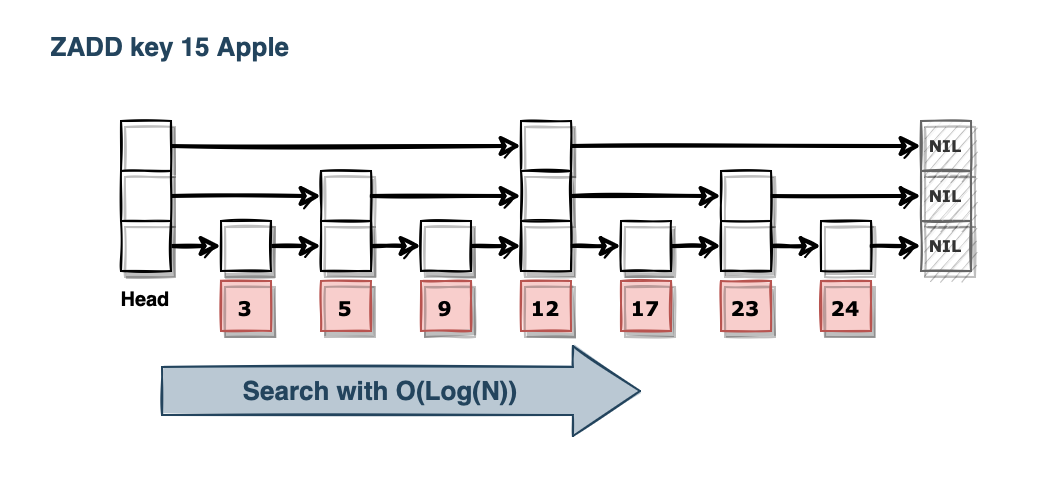
먼저 입력한 스코어는 스킵 리스트에 저장되는데, 스킵 리스트를 스캔하여 추가할 노드의 위치를 찾습니다. 이 과정에서 O(log(N))의 처리 시간이 소요됩니다. 만일 중복된 스코어가 존재한다면 멤버 문자열을 기준으로 정렬합니다.
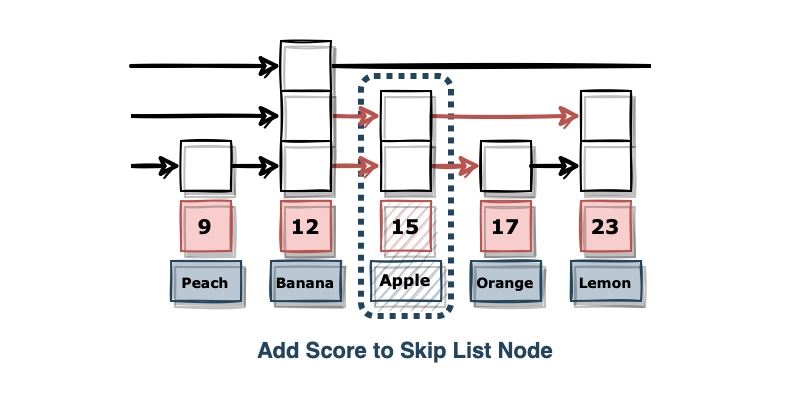
스킵 리스트 노드에는 스코어와 멤버 문자열 및 레벨별 노드 연결 정보가 저장됩니다. 스킵 리스트에 새로운 노드를 넣어주고 전후 연결된 레벨(Level)을 다시 조정해 줍니다. 일반적으로 Sorted Set에서는 레벨을 32개까지 관리하고 있습니다.
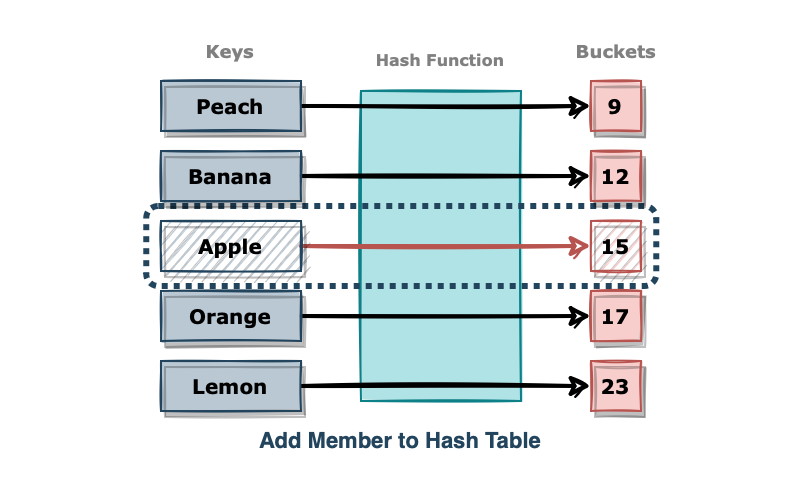
그 후 해시 테이블에 멤버 문자열을 key 값으로 하여 버킷에 스코어를 넣어줍니다.
1.2 ZREM
입력했던 멤버를 지우기 위해서는 ZREM를 사용합니다.
> ZREM key1 value1
(integer) 1 # 성공적으로 삭제된 경우 true 반환
해당 과정에서 입력한 멤버와 연결된 스코어가 해시 테이블에서 제거됩니다. 또한 스코어가 존재는 노드를 찾기 위해 스킵 리스트를 탐색하는데, 이 과정에서 O(Log(N)) 만큼의 처리 시간이 소요됩니다. 노드를 찾았으면 해당 노드를 제거하고 전후 노드를 다시 이어줍니다.
1.3 ZRANK
특정 원소의 순위를 조회하는 경우에는 ZRANK 명령어를 사용할 수 있습니다. Rank는 0부터 시작합니다.
> ZADD key2 123 first
(integer) 1
> ZADD key2 111 second
(integer) 1
> ZADD key2 999 third
(integer) 1
> ZRANK key2 second
(integer) 0 # 처음 rank는 0부터 시작
Rank를 계산하는 경우에 스킵 리스트 노드의 span이라는 변수를 이용합니다.
해당 값은 노드의 레벨마다 저장되는데, 다음 가리키는 노드가 몇 번째 뒤에 있는지 기록되어 있습니다.
스킵 리스트에 노드가 추가되거나 제거될 때마다 인근 노드의 span 값이 갱신됩니다.
따라서 rank를 계산할 때 스코어와 멤버가 일치하는 노드를 탐색하는 과정에서 거쳐 간 레벨의 span 값을 모두 더하면 그 값이 바로 rank 입니다.
![]()
위의 예시에서 4 + 1 + 1을 계산하여 6번째 위치한 것을 알 수 있으며, rank는 0부터 시작하기 때문에 1을 빼준 값 5가 바로 rank가 됩니다. 이때 시간 복잡도는 O(log(N)) 입니다.
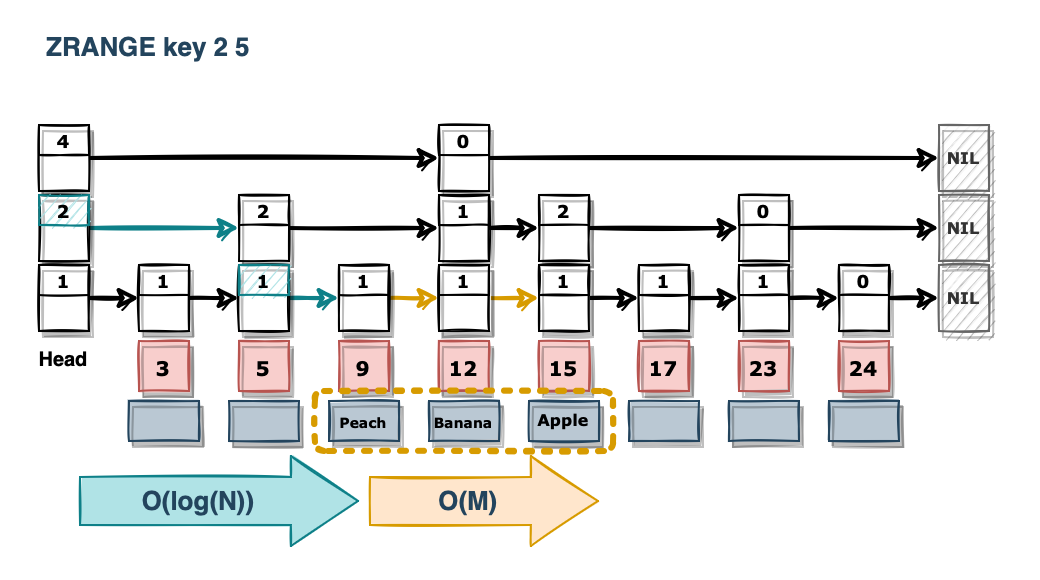
1.4 ZRANGE
조회하는 경우에는 ZRANGE를 사용할 수 있습니다. 뒤에 시작 인덱스, 종료 인덱스까지 입력해 주어야 합니다. 인덱스는 0부터 시작하며 score 기준 오름차순으로 반환합니다.
> ZRANGE key2 0 10 # score 기준 오름차순으로 처음 10개 반환
1) "second"
2) "first"
3) "third"
ZREVRANGE 명령어로 내림차순으로 조회할 수 있습니다.
> ZREVRANGE key2 0 10
1) "third"
2) "first"
3) "second"
ZRANGE 연산을 수행할 때 시간 복잡도는 Sorted Set의 모든 멤버 개수를 N, 출력하는 데이터의 개수를 M이라고 할 때 O(log(N) + M) 입니다. 위에서 설명한 로직과 유사하게 span 값을 계산하여 처음 출력할 노드를 찾고, 해당 부분에서 종료 인덱스에 다다를 때까지 다음 노드로 넘어가면서 멤버를 반환합니다.
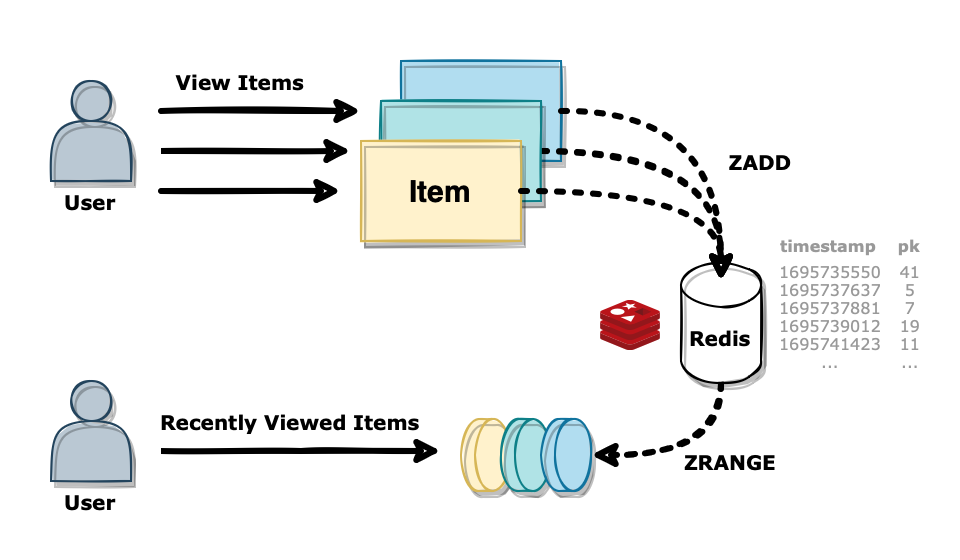
2. Recently Viewed Item
위와 같은 특성을 활용하여 Redis Set 자료 구조를 최근 본 상품 기능에 적용할 수 있습니다. 해당 기능을 구현하기 위해 Sorted Set에 데이터를 적재하는 부분과 가져오는 부분이 모두 필요합니다.
2.1 Apply!
먼저 상품 조회 시마다 Sorted Set에 ZADD 명령어로 상품 정보를 저장합니다. 사용자마다 조회한 상품 리스트를 구분하기 위해 사용자 PK와 같은 고유한 값을 이용하여 키값을 설정할 수 있습니다. 멤버로는 상품을 구분할 수 있는 PK 값을 입력하며, 조회 당시의 timestamp 값을 스코어로 입력합니다. 해당 방식을 통해 사용자마다 조회한 시점 순으로 상품의 PK가 입력됩니다.
이제 최근 조회 리스트는 Sorted Set에 쌓인 순서대로 가져오기만 하면 됩니다. 최신순으로 가져와야 하므로 ZREVRANGE 구문을 이용하여 아이템의 PK를 가져옵니다. 시작 인덱스, 종료 인덱스를 활용하여 자연스럽게 페이지네이션도 가능합니다.
2.2 Furthermore..
그 외에 비즈니스적으로 고려할 사항이 더 있습니다.
위 로직대로 적용하면 Sorted Set이 계속 쌓이게 됩니다. 일정 개수 이상이 되면 낮은 score를 가진 멤버부터 제거하던지, 아니면 아예 Sorted Set에 만료 시간을 설정하여 일정 시간 뒤에 삭제되도록 하는 방법이 있습니다.
Sorted Set에 상품 PK가 아닌 상품 정보를 저장하는 방법도 있습니다. 이 방법을 활용하면 최근 본 상품 목록 조회 시에 Sorted Set에서 가져온 PK들로 데이터베이스를 다시 조회하는 과정을 줄일 수도 있습니다. 다만 상품 정보를 저장하는 과정에서 조금이라도 상품 정보가 변경된다면 중복된 상품이 저장될 수도 있습니다.
2.3 Source Code
위의 내용을 구현한 코드를 첨부합니다. 코틀린 스프링 기반으로 작성하였습니다.
/**
* RedisSet 관리 클래스
*/
@Component
class RecentlyViewedItemManager {
@Autowired
private lateinit var redissonClient: RedissonClient
private fun getKey(userId: Long) = "recent-view-$userId"
private fun getSortedSet(userId: Long): RScoredSortedSet<String> {
return redissonClient.getScoredSortedSet(getKey(userId), StringCodec.INSTANCE)
}
fun add(userId: Long, itemId: Long) {
try {
val sortedSet = getSortedSet(userId)
sortedSet.add(
LocalDateTime.now().toEpochSecond(ZoneOffset.UTC).toDouble(),
itemId.toString()
)
} catch (e: Exception) {
logger.error("Redis SortedSet Error - user=$userId item=$itemId", e)
}
}
fun getList(userId: Long): List<Long> {
val sortedSet = getSortedSet(userId)
return sortedSet.valueRangeReversed(0, 10).map { str -> str.toLong() }
}
}
위와 같이 Redis Set을 관리하는 클래스를 구성할 수 있습니다. 레디스와 연결을 위해 redisson 라이브러리를 사용하였습니다.
아래에는 각 서비스 계층에서 사용할 수 있도록 비즈니스 로직에 추가하였습니다.
@Service
class ItemService {
@Autowired
private lateinit var itemRepository: ItemRepository
@Autowired
private lateinit var recentlyViewedItemManager: RecentlyViewedItemManager
/**
* 상품 조회시마다 RedisSet에 상품 pk 저장
*/
fun getItem(userId: Long, itemId: Long): Item {
val item = itemRepository.findByIdOrNull(itemId) ?: throw Exception("Item not found!")
recentlyViewedItemManager.add(userId, itemId)
return item
}
}
@Service
class UserRecentViewService {
@Autowired
private lateinit var itemRepository: ItemRepository
@Autowired
private lateinit var recentlyViewedItemManager: RecentlyViewedItemManager
/**
* RedisSet에서 score 역순으로 최근 본 상품 목록 조회
*/
fun getUserRecentView(userId: Long): List<Item> {
val itemIdList = recentlyViewedItemManager.getList(userId)
if (itemIdList.isEmpty()) {
return listOf()
}
return itemRepository.findByIdIn(itemIdList).sortedBy { item -> itemIdList.indexOf(item.id) }
}
}
References
- Redis sorted sets | Redis
- GitHub - redis/redis
- SORTED SETS Introduction Redis
- Redis SKIP List of ZSETS(SORTED SETS)
- 최근 본 상품 pagination은 어떻게 할까?