
저번 포스트에서 간단히 Airflow의 구조에 대해 살펴보았다면 이번에는 Airflow를 직접 실행해 봅시다.
아래에 설명된 내용들은 다음 환경 기준으로 작성되었습니다.
- Python 3.11
- Apache Airflow 2.6.3
- PostgreSQL 12.14
1. Installation
Airflow는 실행 시 홈 디렉토리가 정의되어 있어야 합니다.
환경변수 AIRFLOW_HOME으로 프로젝트의 홈 디렉토리를 정의할 수 있습니다.
해당 값이 설정되지 않으면 ~/airflow 경로를 디폴트로 잡아 루트 경로에 새 프로젝트가 생성될 수 있으니 빼먹지 않도록 주의합니다.
현재 위치 기준으로 airflow/ 경로를 홈 디렉토리로 설정하였습니다.
$> export AIRFLOW_HOME=./airflow
pip를 이용해서 Airflow를 설치합니다.
$> pip install apache-airflow
$> airflow version
2.6.3
아래와 같이 AIRFLOW_HOME 경로에 프로젝트가 생성되었습니다.
$> tree
.
└── airflow
├── airflow.cfg # Airflow Config 파일
├── logs/ # 로그 디렉토리
└── webserver_config.py # 웹서버 Config 파일
airflow.cfg 파일은 아래서 설명할 Airflow 설정 파일입니다.
logs 디렉토리 하위에는 스케줄러 및 워커의 로그가 기록됩니다.
webserver_config.py 파일은 Airflow 웹서버 설정 파일입니다.
2. Configuration
Airflow를 구성하는 환경 설정값들은 airflow.cfg 파일에서 관리합니다.
필요한 경우 해당 설정 파일의 변수들을 입맛에 맞게 조정할 수 있습니다.
해당 설정 파일은 Airflow 실행 시에 반드시 AIRFLOW_HOME 디렉토리에 위치하고 있어야 인식할 수 있습니다.
아래에 주로 많이 사용하는 값들을 나열해 보았는데, 더 자세한 내용을 보고 싶으면 공식 문서 링크를 참고 부탁드립니다.
[core]
dags_folder: DAG파일이 존재하는 디렉토리.default_timezone: 기본 타임존.executor: 스케줄러에서 사용할 executor 클래스. (이전 포스트의 Executor 설명 참조)parallelism: 동시에 실행 가능한 최대 Task 개수max_active_tasks_per_dag: 각 DAG 마다 동시에 실행될 수 있는 task의 최대 개수max_active_runs_per_dag: 동시에 실행될 수 있는 DAG의 최대 개수load_examples: 예제 DAG 파을을 불러오는 여부. 큰 이슈가 없다면False로 설정합니다.plugins_folder: 플러그인 폴더 경로
[database]
sql_alchemy_conn: 메타 데이터베이스 커넥션 정보
[webserver]
secret_key: Flask 어플리케이션에서 사용할 secert 키workers: 어플리케이션을 구동시킬 gunicorn 워커 개수
[scheduler]
scheduler_idle_sleep_time: 스케줄러 루프를 한번 수행하고 다음 작업을 위해 대기하는 시간min_file_process_interval: DAG 파일을 파싱하기 위해 큐에 넣는 최소 주기(초). 기본적으로 30초로 되어있으나 더 짧게 설정할수록 자주 파싱을 수행하게 되어 CPU 자원을 많이 소모합니다.dag_dir_list_interval: DAG 디렉토리를 스캔하여 리스트를 갱신하는 주기parsing_processes: DAG 파일을 파싱할 때 동시에 spawn 되는 DagFileProcessor 프로세스의 최대 개수
위의 내용을 바탕으로 프로젝트의 일부분을 수정하였습니다.
[core]
load_examples = False
default_timezone = Asia/Seoul
executor = LocalExecutor
parallelism = 3
[database]
sql_alchemy_conn = postgresql+psycopg2://<user>:<password>@<host>/<db>
LocalExecutor를 사용하기 위해 기본적으로 sqlite로 설정되어 있던 메타 데이터베이스를 PostgreSQL로 변경하였습니다.
LocalExecutor에서는 parallelism 값만큼 워커 프로세스를 실행하는데 최대 3개까지 실행할 수 있도록 하였습니다.
만일 0으로 설정한 경우에는 Task 실행 시마다 워커 프로세스가 spawn 됩니다.
3. Initialize Database
PostgreSQL을 사용하기 위해 아래 라이브러리를 설치힙니다.
$> pip install psycopg2
아래 명령어를 실행하여 메타 데이터베이스를 초기화합니다.
$> airflow db init
초기 실행시 여러 테이블이 생성되는데 주요 테이블은 아래와 같습니다.
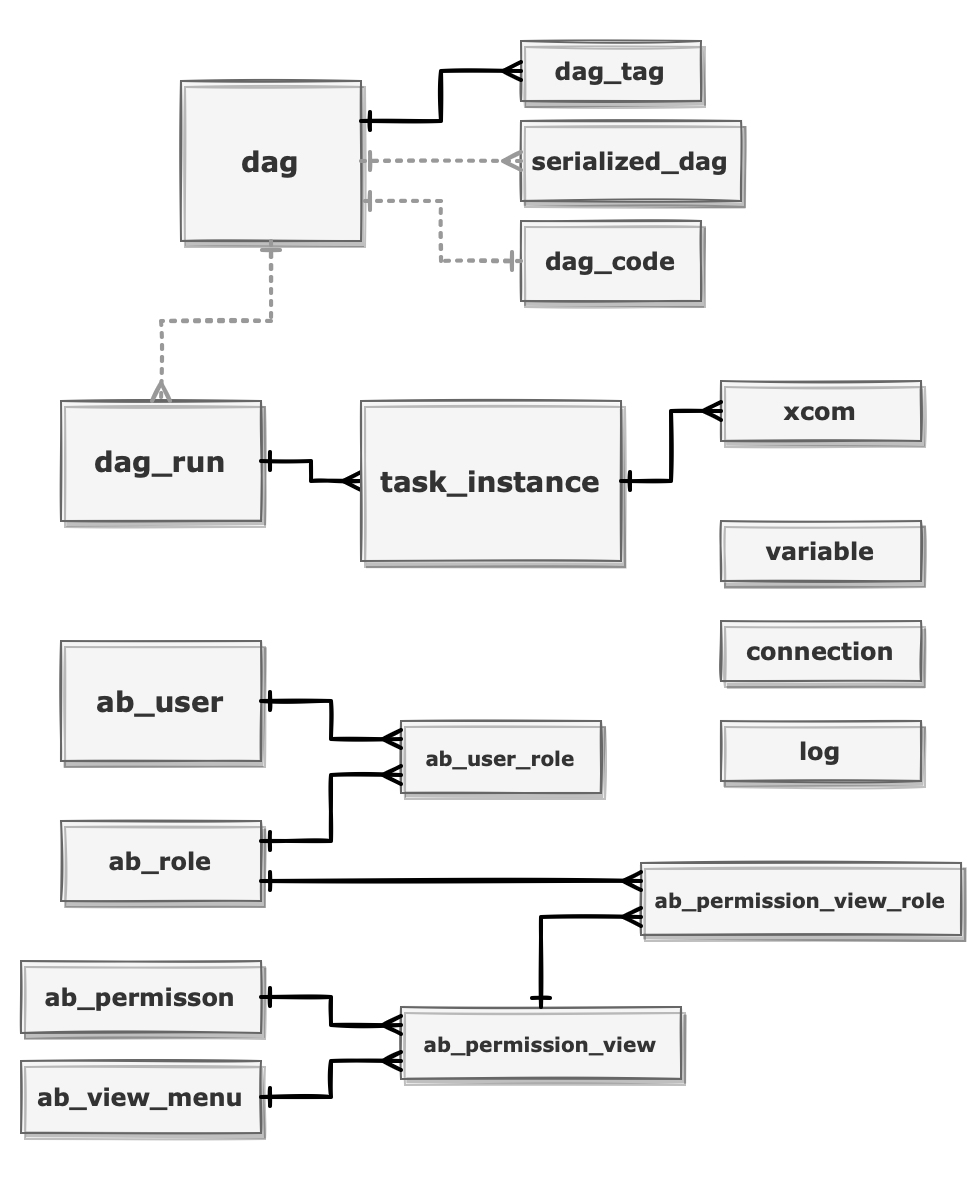
- dag: DAG 메타 정보
- serialized_dag: DAG 및 Task 정보를 JSON 형식으로 파싱한 데이터
- dag_code: DAG 파이썬 소스코드 전문
- dag_run: DAG run 실행 이력
- task_instance: Task instance 실행 이력
- xcom: 작업 실행시 Task instance 간에 전달할 데이터
- ab_user: 사용자 정보 테이블
- variable: 작업시 필요한 변수들을 key-value 형식으로 저장한 데이터
- connection: 데이터베이스 연결 정보
- log: CLI 혹은 인터페이스에서 실행되는 이벤트 기록
4. Scheduler
아래 명령어를 이용하여 scheduler를 실행할 수 있습니다.
$> airflow scheduler
아래와 같은 테스트 DAG를 작성합니다.
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
import pendulum
DAG_ID = "sample_dag"
with DAG(
dag_id=DAG_ID,
description="샘플 코드",
schedule="0 0 * * *",
start_date=pendulum.datetime(2021, 1, 1, tz="Asia/Seoul"),
catchup=False,
) as dag:
def echo():
print("Running Airflow~")
first_task = BashOperator(
task_id=f"{DAG_ID}__first",
bash_command="echo start!",
)
second_task = PythonOperator(
task_id=f"{DAG_ID}__second",
python_callable=echo,
)
finalize_task = BashOperator(
task_id=f"{DAG_ID}__finalize",
bash_command="echo finish!",
)
first_task >> second_task
for i in range(3):
task_i = BashOperator(
task_id=f"{DAG_ID}__task_{i}",
bash_command=f"echo 'running task {i}' && sleep 1",
)
second_task >> task_i >> finalize_task
여러 operator 클래스를 이용하여 Task를 정의할 수 있으며, Task간에 >> 연산자 혹은 set_downstream() 메소드를 이용하여 연결할 수 있습니다.
DAG 파일 작성 후 스케줄러가 돌아서 적당한 시간이 되면 해당 파일이 파싱 되어 메타 데이터베이스에 저장됩니다. 아래 명령어로 현재 등록된 DAG 리스트를 확인해 볼 수 있습니다.
$> airflow dags list
dag_id | filepath | owner | paused
===========+=======================================+=========+=======
sample_dag | /your/airflow/home/dags/sample_dag.py | airflow | True
아래 명령어를 입력하여 작성한 DAG를 실행해 볼 수 있습니다.
$> airflow dags test sample_dag
5. Webserver
아래 명령어를 입력하여 사용자를 생성할 수 있습니다.
$> airflow users create \
--username miintto \
--firstname Park \
--lastname Minjae \
--role Admin \
--email admin@miintto.com
Password:
입력한 패스워드는 웹서버 접속 시 필요하므로 꼭 기억해 두도록 합니다.
$> airflow webserver
웹서버는 기본적으로 8080 포트로 실행됩니다. http://localhost:8080 경로로 웹서버에 접속할 수 있습니다.
사용자 생성시 입력했던 username과 비밀번호를 입력하여 로그인힙니다.
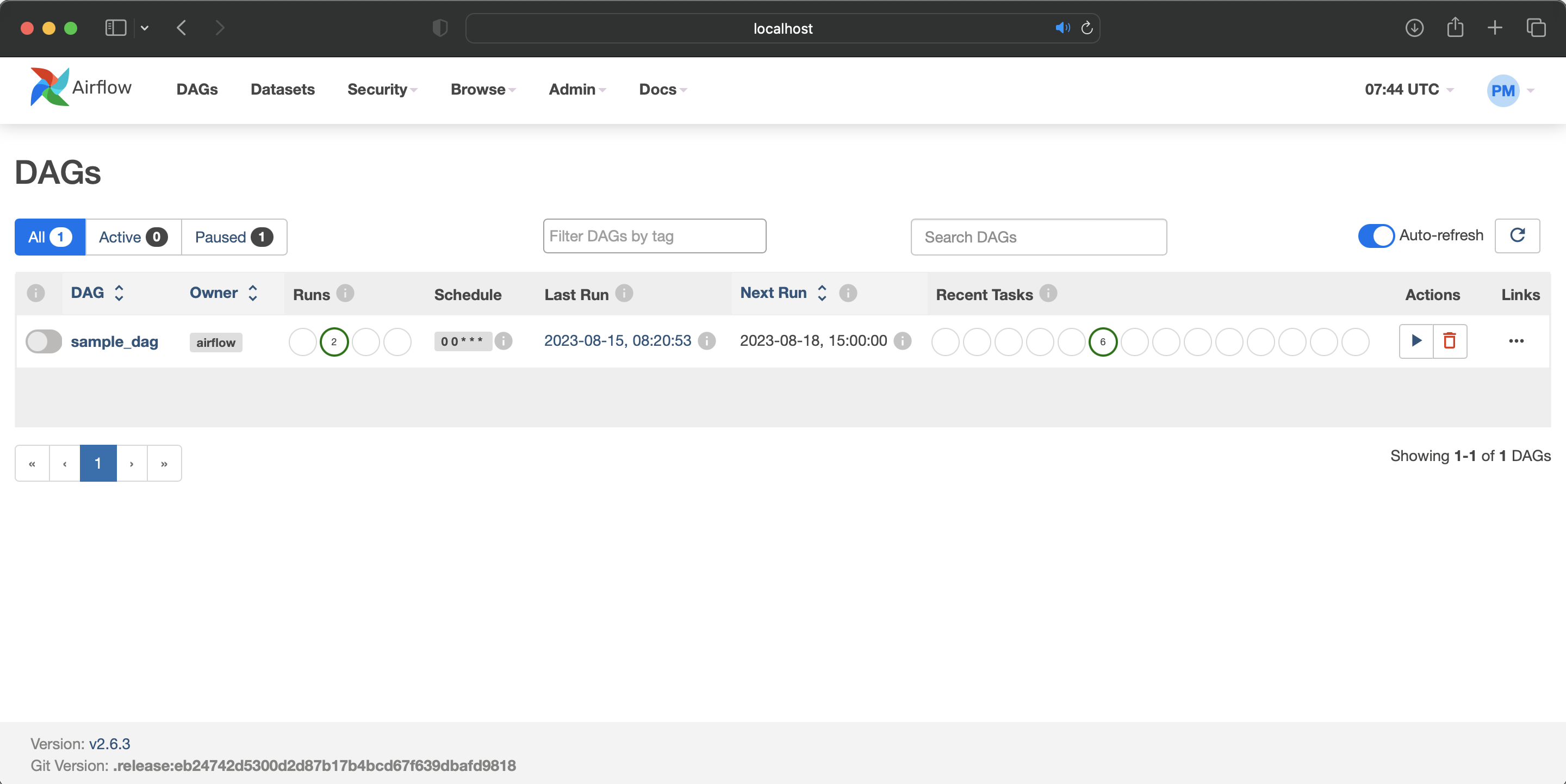
메인 대시보드 화면에서 작성했던 DAG 리스트 및 Task 실행 현황을 모니터링 할 수 있습니다.
References
- Bas Harenslak & Julian de Ruiter, 『Data Pipeline with Apache Airflow』, 김정민 & 문선홍, 제이펍, 2022-03-16
- Quick Start — Airflow Documentation