
예전 파이썬의 가비지 컬렉션에 대해 찾아보면서 인스타그램이 GC를 비활성화여 메모리 자원에 이득을 보았다는 포스트를 보았습니다. 하지만 1년도 채 되지 않아 다시 활성화했다는 아래 게시글을 접하게 되었는데요. 두 포스트 모두 문제를 발견하고 여러 가설을 세워 해결하는 과정이 인상적이었습니다. 파이썬 인터프리터의 기본 구조와 동작 원리에 대한 이해를 돕는 데 좋을 것 같아 두고두고 읽으려고 번역해 두었습니다.
해당 포스트는 Instagram Engineering 블로그의 Copy-on-write friendly Python garbage collection 포스트를 번역한 글입니다.
게시일: 2017.12.21
Copy-on-write에 친화적인 파이썬 가비지 컬렉션
인스타그램은 세상에서 가장 큰 규모의 순수하게 파이썬으로 작성된 Django 서버를 운영하고 있습니다. 초창기에는 단순한 매력에 끌려 때문에 파이썬을 메인 언어로 선택하였고 점점 규모가 커져감에도 이러한 단순함을 유지하고자 몇 년간 여러 편법을 사용해 왔습니다. 작년에는 파이썬 GC를 비활성화하는 방식을 도입하여 사용하지 않는 메모리 자원을 확보하였고 약 10%의 성능상 이득을 보기도 했습니다. 하지만 인스타그램 엔지니어링 팀이 커지고 새 기능들이 점점 추가되면서 메모리 사용량도 점진적으로 증가하였고, 결국 GC를 비활성화하면서 얻은 이득이 다시 무용지물이 되기 시작했습니다.
아래 차트에서 서버 요청량에 따른 메모리 사용량을 나타내 보았는데, 요청이 3,000건이 넘어가자 600MB 이상의 메모리가 사용되는 것을 확인할 수 있습니다. 여기서 주목할 점은 메모리 사용량이 지속적으로 증가하는 추세라는 점입니다.
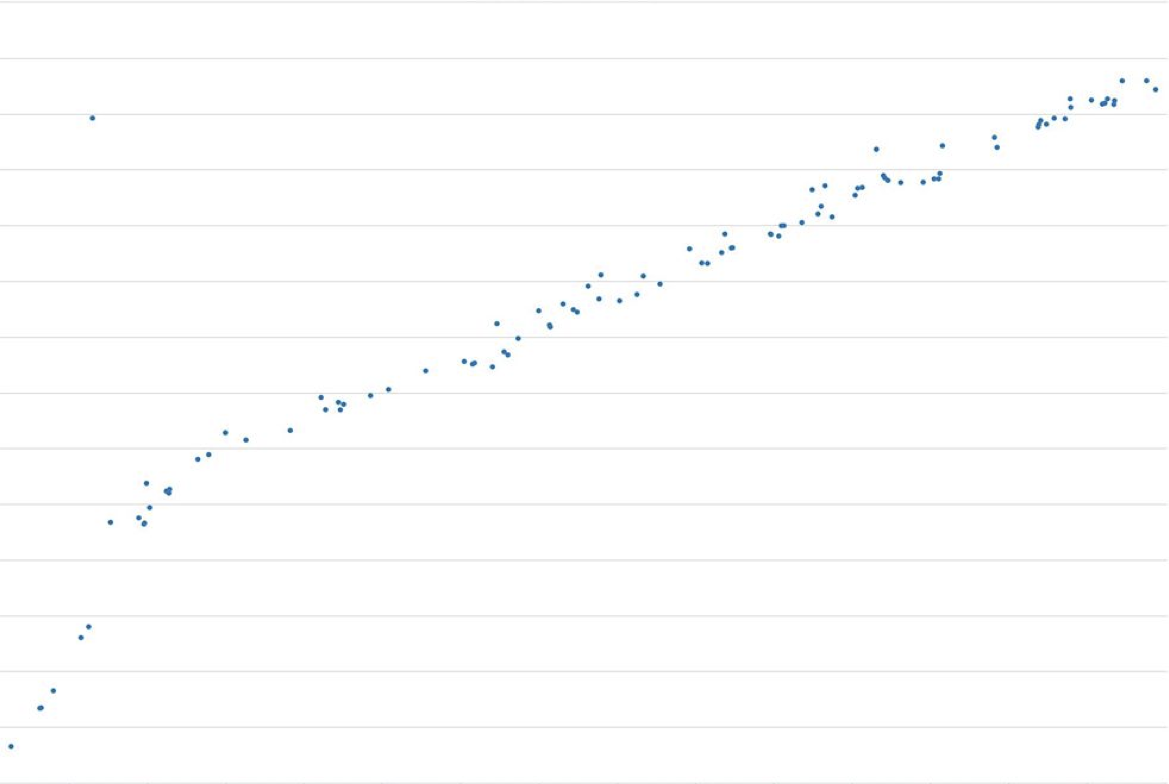
부하 테스트 결과 메모리 사용량이 병목 지점임을 확인할 수 있었습니다. GC를 다시 활성화함으로써 이 현상을 완화시켰고 메모리 증가율도 소폭 감소했지만, Copy-on-write(COW)는 여전히 메모리 공간을 잡아먹고 있었습니다. 그래서 우리는 COW와 그로 인한 메모리 오버헤드 없이 파이썬 GC를 작동시킬 수 있을지 확인해 보기로 했습니다.
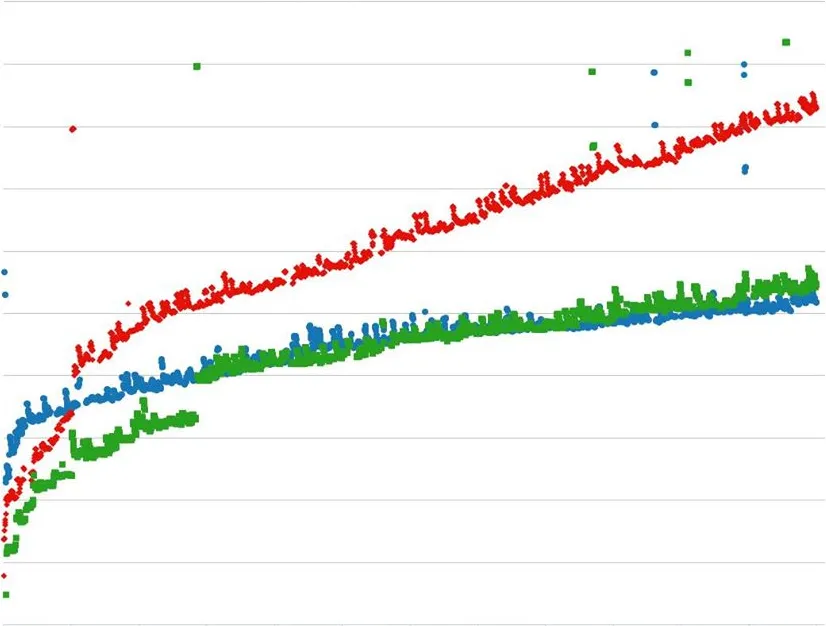 빨강: GC 비활성화 / 파랑: 명식적으로 GC 호출 / 초록: 기본 Python GC 활성화
빨강: GC 비활성화 / 파랑: 명식적으로 GC 호출 / 초록: 기본 Python GC 활성화
첫 번째 시도: GC 헤드 데이터 구조체를 재구성
저번 GC 포스트에서도 설명했듯이 COW가 발생하는 원인은 각각의 파이썬 객체의 헤드 부분에 있습니다.
/* GC information is stored BEFORE the object structure. */
typedef union _gc_head
{
struct {
union _gc_head *gc_next;
union _gc_head *gc_prev;
Py_ssize_t gc_refs;
} gc;
long double dummy; /* force worst-case alignment */
} PyGC_Head;
컬렉션 작업이 진행될 때마다 대상이 되는 모든 객체에 대해 gc_refs 값을 ob_refcnt 값으로 업데이트 하는데, 이 쓰기 작업이 메모리에 COW를 발생시키게 됩니다.
해결책은 명백한데 바로 모든 헤드를 다른 메모리로 가져와 조밀하게 저장해야 한다는 것입니다.
이를 위해 컬렉션 작업 중에는 gc_head 구조체의 포인터에 변동이 없도록 새로운 버전을 만들어 보았습니다.
typedef union _gc_head_ptr
{
struct {
union _gc_head *head;
} gc_ptr;
double dummy; /* force worst-case alignment */
} PyGC_Head_Ptr;
그리고 잘 작동하는지 확인하기 위해 아래와 같이 스크립트를 작성하여 메모리를 할당하고 하위 프로세스의 메모리 사용량을 지켜보았습니다.
lists = []
strs = []
for i in range(16000):
lists.append([])
for j in range(40):
strs.append(' ' * 8)
기존 gc_head 구조체 기반으로 실행해 보았을 때 하위 프로세스의 RSS 메모리 사용량은 60MB까지 치솟았습니다. 반면 새로 작성한 구조체로 실행한 경우에는 메모리가 0.9MB 정도 밖에 사용되지 않았습니다. 기능상 제대로 작동한것 처럼 보여집니다.
하지만 작성한 소스 코드를 잘 살펴보면 기존 구조체에 2개의 포인터를 추가로 할당하며 16바이트의 메모리를 더 사용하게 되어있습니다. 16바이트라는 수치가 비록 미미해 보일 수 있지만 모든 파이썬 객체에 대해 적용된다고 보면 각 서버에 꽤 심한 부담이 될 수 있습니다. (대략적으로 하나의 프로세스에 백만 개의 파이썬 객체가 있고 한 서버당 약 70개의 프로세스가 실행되고 있습니다.)
16 bytes* 1,000,000 * 70 = ~1 GB
두 번째 시도: GC에서 공유 객체를 숨기는 방법
새로 작성한 구조체가 단순 메모리 수치로는 이점을 보여주었지만 소폭의 메모리 오버헤드가 발생했다는 점에서 바람직하지 않았습니다. 우리의 목표는 별다른 성능의 영향 없이 파이썬 GC를 다시 활성화할 방법을 찾는 것이었습니다. 이러한 COW 문제는 단지 하위 프로세스가 포크 되기 이전에 메인 프로세스에서 생성된 공유 객체에서만 발생했기 때문에 파이썬 GC가 공유 객체를 다른 방식으로 접근하도록 시도해 보았습니다. 간단히 말해서 공유되고 있는 객체들을 GC 과정에서 숨겨두어 컬렉션 주기에서 제외할 수만 있다면 문제를 해결할 수 있습니다.
이를 위해 우리는 파이썬 GC 모듈에 gc.freeze()라는 간단한 API를 추가했습니다.
해당 메소드는 컬렉션 작업 시 대상 객체를 추적하는 파이썬 GC generation 리스트에서 특정 객체를 제거하는 작업을 수행하게 됩니다.
추가된 API는 CPython 오픈소스에 반영되었고 Python3.7 부터 사용할 수 있습니다.
(https://github.com/python/cpython/pull/3705)
static PyObject *
gc_freeze_impl(PyObject *module)
{
for (int i = 0; i < NUM_GENERATIONS; ++i) {
gc_list_merge(GEN_HEAD(i), &_PyRuntime.gc.permanent_generation.head);
_PyRuntime.gc.generations[i].count = 0;
}
Py_RETURN_NONE;
}
성공!
우리는 해당 작업 내용을 운영 서버에 배포하였고, 마침내 우리가 예상했던 대로 작동하였습니다. COW는 더 이상 발생하지 않았으며 공유 메모리도 안정적으로 유지되었고 요청당 평균 메모리 증가율도 50% 이하로 떨어졌습니다. 아래 차트는 GC를 다시 허용하면서 메모리 사용량이 지속적으로 증가하지 않고 프로세스 수명을 늘려주면서 효율적으로 메모리 자원이 사용되는 것을 보여줍니다.
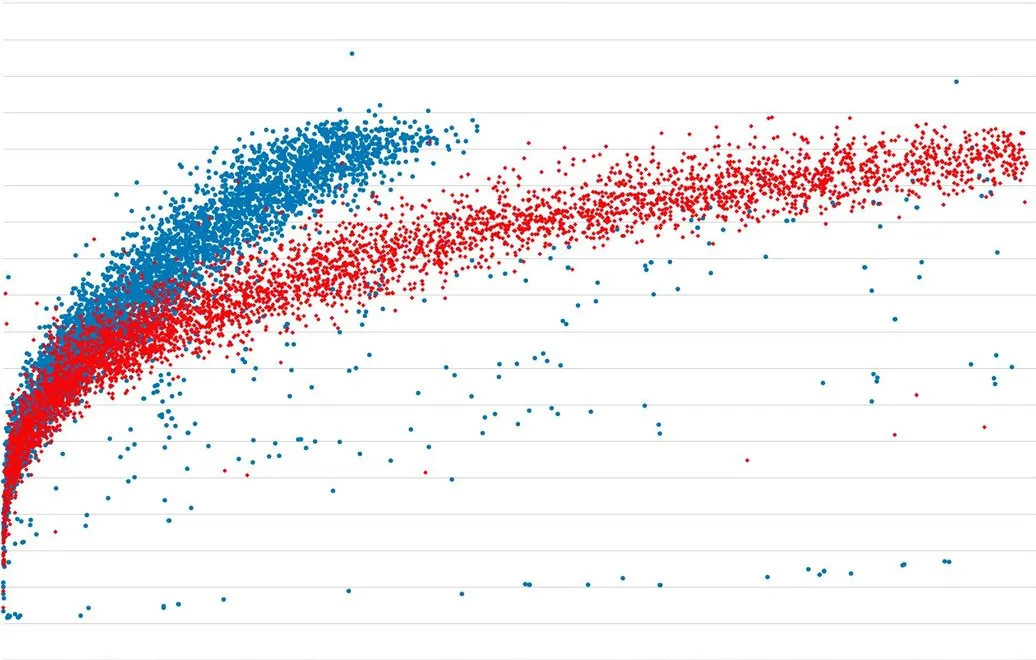 파랑: GC 비활성화 / 빨강: 자동 GC
파랑: GC 비활성화 / 빨강: 자동 GC
원문 보기
Copy-on-write friendly Python garbage collection
At Instagram, we have the world’s largest deployment of the Django web framework, which is written entirely in Python. We began using Python early on because of its simplicity, but we’ve had to do many hacks over the years to keep it simple as we’ve scaled. Last year we tried dismissing the Python garbage collection (GC) mechanism (which reclaims memory by collecting and freeing unused data), and gained 10% more capacity. However, as our engineering team and number of features have continued to grow, so has memory usage. Eventually, we started losing the gains we had achieved by disabling GC.
Here’s a graph that shows how our memory grew with the number of requests. After 3,000 requests, the process used ~600MB more memory. More importantly, the trend was linear.
From our load test, we could see that memory usage was becoming our bottleneck. Enabling GC could alleviate this problem and slow down the memory growth, but undesired Copy-on-write (COW) would still increase the overall memory footprint. So we decided to see if we could make Python GC work without COW, and hence, the memory overhead.
Red: without GC; Blue: calling GC collect explicitly; Green: default Python GC enabled
First try: redesign the GC head data structure
If you read our last GC post carefully, you’ll notice the culprit of the COW was ahead of each python object:
/* GC information is stored BEFORE the object structure. */
typedef union _gc_head
{
struct {
union _gc_head *gc_next;
union _gc_head *gc_prev;
Py_ssize_t gc_refs;
} gc;
long double dummy; /* force worst-case alignment */
} PyGC_Head;
The theory was that every time we did a collection, it would update the gc_refs with ob_refcnt for all tracked objects — but unfortunately this write operation caused memory pages to be COW-ed. A next obvious solution was to move all the head to another chunk of memory and store densely.
We implemented a version where the pointer in the gc_head struct didn’t change during collection:
typedef union _gc_head_ptr
{
struct {
union _gc_head *head;
} gc_ptr;
double dummy; /* force worst-case alignment */
} PyGC_Head_Ptr;
Did it work? We used the following script to allocate the memory and fork a child process to test it:
lists = []
strs = []
for i in range(16000):
lists.append([])
for j in range(40):
strs.append(' ' * 8)
With the old gc_head struct, the child process’s RSS memory usage increased by ~60MB. Under the new data structure with the additional pointer, it only increased by ~0.9 MB. So it worked!
However, you may have noticed the additional pointer in the proposed data structure introduced memory overhead (16 bytes — two pointers). It seems like a small number, but if you consider it applied to every collectable Python object (and we usually have millions of objects in one process, with ~70 processes per host), it could be a fairly big memory overhead on each server.
16 bytes* 1,000,000 * 70 = ~1 GB
Second try: hiding shared objects from GC
Even though the new gc_head data structure showed promising gains on memory size, its overhead was not ideal. We wanted to find a solution that could enable the GC without noticeable performance impacts. Since our problem is really only on the shared objects that are created in the master process before the child processes are forked, we tried letting Python GC treat those shared objects differently. In other words, if we could hide the shared objects from the GC mechanism so they wouldn’t be examined in the GC collection cycle, our problem would be solved.
For that purpose, we added a simple API as gc.freeze() into the Python GC module to remove the objects from the Python GC generation list that‘s maintained by Python internal for tracking objects for collection. We have upstreamed this change to Python and the new API will be available in the Python3.7 release (https://github.com/python/cpython/pull/3705))
static PyObject *
gc_freeze_impl(PyObject *module)
{
for (int i = 0; i < NUM_GENERATIONS; ++i) {
gc_list_merge(GEN_HEAD(i), &_PyRuntime.gc.permanent_generation.head);
_PyRuntime.gc.generations[i].count = 0;
}
Py_RETURN_NONE;
}
Success!
We deployed this change into our production and this time it worked as expected: COW no longer happened and shared memory stayed the same, while average memory growth per request dropped ~50%. The plot below shows how enabling GC helped the memory growth by stopping the linear growth and making each process live longer.
Blue: is no-GC; Red: auto-GC
References